
SQL SERVER大話存儲結構(3)_數據行的行結構
阿新 • • 發佈:2017-05-18
bits 基礎 就會 mar ant rain 版權 bpa 一個數
一行數據是如何來存儲的呢?
變長列與定長列,NULL與NOT NULL,實際是如何整理存放到 8k的數據頁上呢?
對表格進行增減列,修改長度,添加默認值等DDL SQL,對行存儲結構又會有怎麽樣的影響呢?
什麽是大對象,什麽是行溢出,存儲引擎是如何處理它們呢?

如果轉載,請註明博文來源: www.cnblogs.com/xinysu/ ,版權歸 博客園 蘇家小蘿蔔 所有。望各位支持!

 各個部分其實都比較好理解,狀態B位未使用,狀態A位,詳細描述如下。
各個部分其實都比較好理解,狀態B位未使用,狀態A位,詳細描述如下。


 可以看到,表格的IAM頁及數據頁全部都改變了,因為當一個堆表添加主鍵變為聚集索引表格的時候,需要重新組織數據頁,按照聚集索引的鍵值順序存儲,所以看到,整個數據頁存儲情況發生了變化。如果是一個大堆表添加聚集索引,那麽這是一個非常耗時及耗費IO、CPU的操作,並且會鎖表直到操作結束,需謹慎操作。
再次來分析現在的行記錄。
dbcc page(‘dbpage‘,1,311,3)
可以看到,表格的IAM頁及數據頁全部都改變了,因為當一個堆表添加主鍵變為聚集索引表格的時候,需要重新組織數據頁,按照聚集索引的鍵值順序存儲,所以看到,整個數據頁存儲情況發生了變化。如果是一個大堆表添加聚集索引,那麽這是一個非常耗時及耗費IO、CPU的操作,並且會鎖表直到操作結束,需謹慎操作。
再次來分析現在的行記錄。
dbcc page(‘dbpage‘,1,311,3)
 可以看到,數據行的內容並沒有發生變化,添加主鍵(聚集唯一索引),會重組整個表格的存儲順序,但是不會影響到行內的數據情況。
可以看到,數據行的內容並沒有發生變化,添加主鍵(聚集唯一索引),會重組整個表格的存儲順序,但是不會影響到行內的數據情況。

 這是一個神奇的處理方式!為啥呢?
仔細查看page的解析內容,發現 :Slot 0 Column 4 Offset 0x0 Length 5 Length (physical) 0 。該列數據長度為5,但是,實際存儲長度為0,也就是這一列壓根沒有存儲在數據頁面中。
個人推測:當添加了NOT NULL列+默認值(非大對象列)的情況下,不對以往數據存儲記錄發生修改,但是在查詢的時候,會判斷該列是否有存儲數據,如果沒有則使用默認值顯示。 這樣有一個非常大的好處:節約存儲空間,不變更行記錄,DDL期間,無需對以往記錄做處理,僅需修改數據字典即可。
3.4.2 大對象列
alter table tbrow add descriptions text not null default ‘i love sql server‘ ;
dbcc traceon(3604)
dbcc ind(‘dbpage‘,‘tbrow‘,-1)
這是一個神奇的處理方式!為啥呢?
仔細查看page的解析內容,發現 :Slot 0 Column 4 Offset 0x0 Length 5 Length (physical) 0 。該列數據長度為5,但是,實際存儲長度為0,也就是這一列壓根沒有存儲在數據頁面中。
個人推測:當添加了NOT NULL列+默認值(非大對象列)的情況下,不對以往數據存儲記錄發生修改,但是在查詢的時候,會判斷該列是否有存儲數據,如果沒有則使用默認值顯示。 這樣有一個非常大的好處:節約存儲空間,不變更行記錄,DDL期間,無需對以往記錄做處理,僅需修改數據字典即可。
3.4.2 大對象列
alter table tbrow add descriptions text not null default ‘i love sql server‘ ;
dbcc traceon(3604)
dbcc ind(‘dbpage‘,‘tbrow‘,-1)
 單薄的表格,一行的記錄,因為添加了大對象列,來了個 LOB data的IAM頁 以及 LOB data的數據頁 。不過,這次僅分析主記錄數據頁面pageid=311。
--主記錄數據頁面pageid=311
dbcc page(‘dbpage‘,1,311,3)
單薄的表格,一行的記錄,因為添加了大對象列,來了個 LOB data的IAM頁 以及 LOB data的數據頁 。不過,這次僅分析主記錄數據頁面pageid=311。
--主記錄數據頁面pageid=311
dbcc page(‘dbpage‘,1,311,3)
 依舊來分析下這行存儲記錄,原先長度都是21,為啥添加了一個 text帶默認值的列,長度就增加為50bytes呢?
這裏註意兩個地方:原先的 task列跟 description列。task列之前是實際不存儲數據內容的,但是現在存儲了數據內容,description大對象列並沒有存儲數據在主記錄中,而是存儲在另外的lob data數據頁中,在主記錄僅存儲 描述 該列具體位置內容,占16bytes。
所以 該行記錄的長度=狀態A+狀態B+定長字段長度+定長字段內容+總列數+null位圖+變長列數量+列偏移矩陣+變長數據內容=1+1+2+(4+10)+2+1+2+2*3+(5+16)= 50 bytes。
來看看這個16進制的字符串:30001200 01000000 78696e79 73752020 20200500 0403001d 00220032 80616c6c 20410000 d1070000 00004b01 00000100 0000,詳細分析這行數據的存儲情況。先把這串字符按照字節數區分,詳細分析及推導見下圖。
依舊來分析下這行存儲記錄,原先長度都是21,為啥添加了一個 text帶默認值的列,長度就增加為50bytes呢?
這裏註意兩個地方:原先的 task列跟 description列。task列之前是實際不存儲數據內容的,但是現在存儲了數據內容,description大對象列並沒有存儲數據在主記錄中,而是存儲在另外的lob data數據頁中,在主記錄僅存儲 描述 該列具體位置內容,占16bytes。
所以 該行記錄的長度=狀態A+狀態B+定長字段長度+定長字段內容+總列數+null位圖+變長列數量+列偏移矩陣+變長數據內容=1+1+2+(4+10)+2+1+2+2*3+(5+16)= 50 bytes。
來看看這個16進制的字符串:30001200 01000000 78696e79 73752020 20200500 0403001d 00220032 80616c6c 20410000 d1070000 00004b01 00000100 0000,詳細分析這行數據的存儲情況。先把這串字符按照字節數區分,詳細分析及推導見下圖。

 可以發現,刪除這一列,對實際數據存儲並沒有影響,但是該列會有一個標識值 DROPPED=[NULL]表明該列已被刪除,註意,這個表示只並不是存儲在每一行數據中,而是數據庫存儲引擎記錄。
截取數據頁面裏邊的16進制內容:30 00 1200 01000000 78696e79737520202020 0500 04 0300 1d0022003280 616c6c2041 0000d107000000004b01000001000000,發現與刪除前的是一樣的,對比如下:
/*
第一個行記錄為刪除前
第二個行記錄為刪除後
30 00 1200 01000000 78696e79737520202020 0500 04 0300 1d0022003280 616c6c2041 0000d107000000004b01000001000000
30 00 1200 01000000 78696e79737520202020 0500 04 0300 1d0022003280 616c6c2041 0000d107000000004b01000001000000
*/
得出結論:刪除一行無數據的列時,不需要修改行內數據存儲情況,僅需要修改涉及的數據字典跟刪除期間持有架構鎖,這是一個非常快的過程(但是如果表格一直被其他用戶進行操作,那麽申請架構鎖也會出現等待情況)。
可以發現,刪除這一列,對實際數據存儲並沒有影響,但是該列會有一個標識值 DROPPED=[NULL]表明該列已被刪除,註意,這個表示只並不是存儲在每一行數據中,而是數據庫存儲引擎記錄。
截取數據頁面裏邊的16進制內容:30 00 1200 01000000 78696e79737520202020 0500 04 0300 1d0022003280 616c6c2041 0000d107000000004b01000001000000,發現與刪除前的是一樣的,對比如下:
/*
第一個行記錄為刪除前
第二個行記錄為刪除後
30 00 1200 01000000 78696e79737520202020 0500 04 0300 1d0022003280 616c6c2041 0000d107000000004b01000001000000
30 00 1200 01000000 78696e79737520202020 0500 04 0300 1d0022003280 616c6c2041 0000d107000000004b01000001000000
*/
得出結論:刪除一行無數據的列時,不需要修改行內數據存儲情況,僅需要修改涉及的數據字典跟刪除期間持有架構鎖,這是一個非常快的過程(但是如果表格一直被其他用戶進行操作,那麽申請架構鎖也會出現等待情況)。
 分析到這裏,可以發現,SQL SERVER在處理刪除列這一塊處理的非常巧妙,最大程度的減少了對表格可用性的影響,無論帶不帶數據,刪除的時候,只處理數據字典類相關內容,標識該列已被刪除,但是實際上沒有去到每一個頁面中去刪除數據,而是把這些列占用的空間在邏輯上修改為不存在,允許以後寫覆蓋。
作為一名小小的DBA,個人覺得在行數據的存儲結構這一塊,針對於增加列或者刪除列的處理,SQL SERVER 設計非常巧妙及高效!相對與 MySQL改進後的Online DDL,SQL SERVER將表格的可用性大大提高以及降低對系統資源的影響。(僅討論列的增加刪除DDL這一塊)
分析到這裏,可以發現,SQL SERVER在處理刪除列這一塊處理的非常巧妙,最大程度的減少了對表格可用性的影響,無論帶不帶數據,刪除的時候,只處理數據字典類相關內容,標識該列已被刪除,但是實際上沒有去到每一個頁面中去刪除數據,而是把這些列占用的空間在邏輯上修改為不存在,允許以後寫覆蓋。
作為一名小小的DBA,個人覺得在行數據的存儲結構這一塊,針對於增加列或者刪除列的處理,SQL SERVER 設計非常巧妙及高效!相對與 MySQL改進後的Online DDL,SQL SERVER將表格的可用性大大提高以及降低對系統資源的影響。(僅討論列的增加刪除DDL這一塊)
 dbcc page(‘dbpage‘,1,334,3)
dbcc page(‘dbpage‘,1,334,3)
 cola列1000個字符,colb列5000個字符,colc列3000個字符,不算其他字節使用,光著3列長度之和就大於8k,按照行溢出的處理,可以推測出 是colb 被移動到 Row-overflow data列,所以,先分析page 334 ,看主記錄的存儲情況,實際情況與推測一致。
cola列1000個字符,colb列5000個字符,colc列3000個字符,不算其他字節使用,光著3列長度之和就大於8k,按照行溢出的處理,可以推測出 是colb 被移動到 Row-overflow data列,所以,先分析page 334 ,看主記錄的存儲情況,實際情況與推測一致。
 pageid=384數據頁面中,存儲3行記錄大概用了6k+的空間,這時候,把id=2的colb列修改為4.5k長度,超過了一個頁面8k的範圍,也就意味著,這個被修改的列會被forword,根據新增的數據頁386,可推測出 forword的列存儲在386中。現在分析 pageid 384來驗證推測。詳見截圖,發現與推測一致。
dbcc page(‘dbpage‘,1,384,3)
pageid=384數據頁面中,存儲3行記錄大概用了6k+的空間,這時候,把id=2的colb列修改為4.5k長度,超過了一個頁面8k的範圍,也就意味著,這個被修改的列會被forword,根據新增的數據頁386,可推測出 forword的列存儲在386中。現在分析 pageid 384來驗證推測。詳見截圖,發現與推測一致。
dbcc page(‘dbpage‘,1,384,3)

如果轉載,請註明博文來源: www.cnblogs.com/xinysu/ ,版權歸 博客園 蘇家小蘿蔔 所有。望各位支持!
1 引入
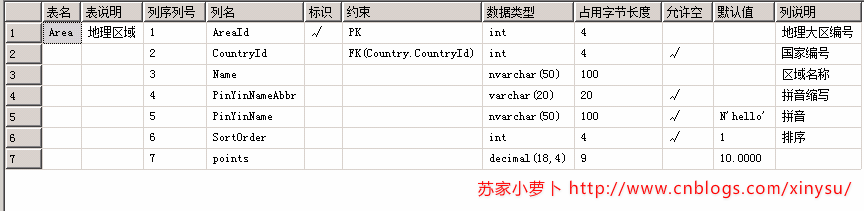
在一個DB內,每一個table都能在sys.sysobjects中找到對應的描述,每一個列,都能從sys.columns中找到說明。 這裏發個SQL是日常管理中使用到的,用於描述一個表格的數據結構情況。
1 SELECT 2 3 表名 = CASE WHEN A.COLORDER=1 THEN D.NAME ELSE ‘‘ END, 4 表說明 = CASE WHEN A.COLORDER=1 THEN ISNULL(F.VALUE,‘‘) ELSE ‘‘ END, 5 列序列號 = A.COLORDER, 6 列名 = A.NAME, 7 標識 = CASE WHEN COLUMNPROPERTY( A.ID,A.NAME,‘ISIDENTITY‘)=1 THEN ‘√‘ELSE ‘‘查詢表結構SQLEND, 8 約束 = CASE WHEN EXISTS( 9 SELECT 1 10 FROM SYSOBJECTS 11 WHERE XTYPE=‘PK‘ AND PARENT_OBJ=A.ID AND NAME IN ( 12 SELECT13 NAME 14 FROM SYSINDEXES 15 WHERE INDID IN( SELECT INDID FROM SYSINDEXKEYS WHERE ID = A.ID AND COLID=A.COLID ) 16 ) 17 ) THEN ‘PK‘ 18 WHEN EXISTS ( 19 SELECT 1 FROM sys.foreign_key_columns 20 WHERE parent_object_id=A.ID AND parent_column_id=A.COLID 21 ) THEN ‘FK‘+‘(‘+(SELECT OBJECT_NAME(referenced_object_id)+‘.‘+COL_NAME(referenced_object_id,referenced_column_id)+‘)‘ FROM sys.foreign_key_columns WHERE parent_object_id=A.ID AND parent_column_id=A.COLID) 22 ELSE ‘‘ END, 23 數據類型 = CASE WHEN B.NAME IN (‘CHAR‘,‘NCHAR‘,‘VARCHAR‘,‘NVARCHAR‘) THEN B.NAME+‘(‘+ISNULL(CAST(case when COLUMNPROPERTY(A.ID,A.NAME,‘PRECISION‘)=-1 then null else COLUMNPROPERTY(A.ID,A.NAME,‘PRECISION‘) end AS VARCHAR(10)),‘MAX‘)+‘)‘ 24 WHEN B.NAME =‘DECIMAL‘ THEN B.NAME+‘(‘+CAST(COLUMNPROPERTY(A.ID,A.NAME,‘PRECISION‘) AS VARCHAR(10))+‘,‘+CAST(ISNULL(COLUMNPROPERTY(A.ID,A.NAME,‘SCALE‘),0) AS VARCHAR(10))+‘)‘ 25 ELSE B.NAME END, 26 占用字節長度 = A.LENGTH, 27 --長度 = COLUMNPROPERTY(A.ID,A.NAME,‘PRECISION‘), 28 --小數位數 = ISNULL(COLUMNPROPERTY(A.ID,A.NAME,‘SCALE‘),0), 29 允許空 = CASE WHEN A.ISNULLABLE=1 THEN ‘√‘ELSE ‘‘ END, 30 默認值 = case when E.TEXT is not null then 31 32 case when substring(e.text,1,2)=‘((‘ then substring(e.text,3,len(e.text)-4) 33 when substring(e.text,1,1)=‘(‘ then substring(e.text,2,len(e.text)-2) 34 else e.text end 35 else ‘‘ end , 36 列說明 = ISNULL(G.[VALUE],‘‘) 37 FROM SYSCOLUMNS A LEFT JOIN SYSTYPES B ON A.XUSERTYPE=B.XUSERTYPE 38 INNER JOIN SYSOBJECTS D ON A.ID=D.ID AND D.XTYPE=‘U‘ AND D.NAME<>‘DTPROPERTIES‘ 39 LEFT JOIN SYSCOMMENTS E ON A.CDEFAULT=E.ID 40 LEFT JOIN sys.extended_properties G ON A.ID=G.major_id AND A.COLID=G.minor_id 41 LEFT JOIN sys.extended_properties F ON D.ID=F.major_id AND F.minor_id=0 42 WHERE D.NAME IN (‘area‘,‘‘,‘‘) 43 ORDER BY A.ID,A.COLORDER
2 數據行
2.1 數據行結構
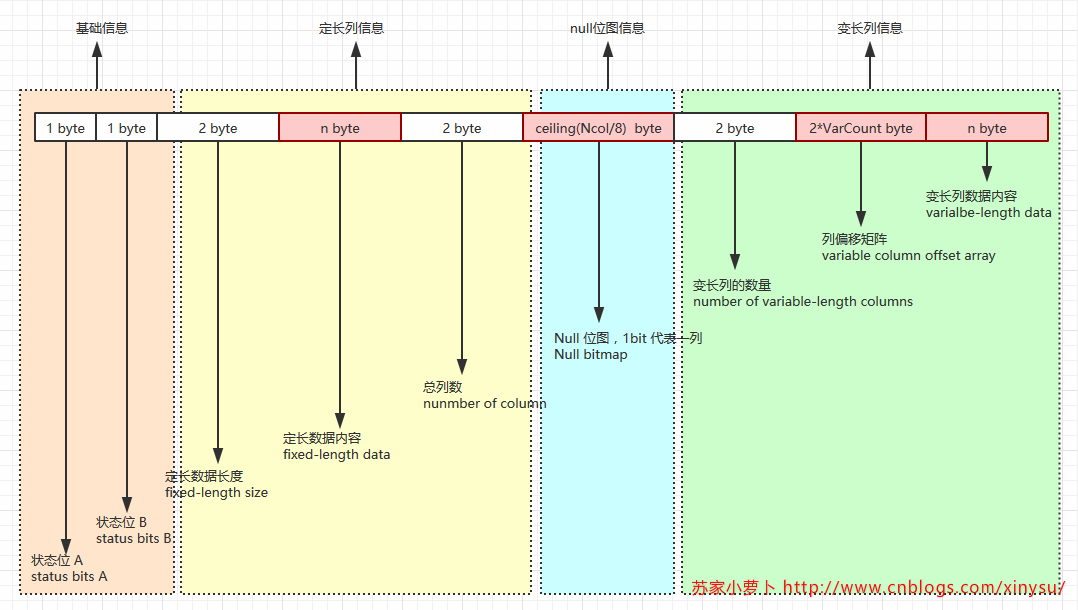
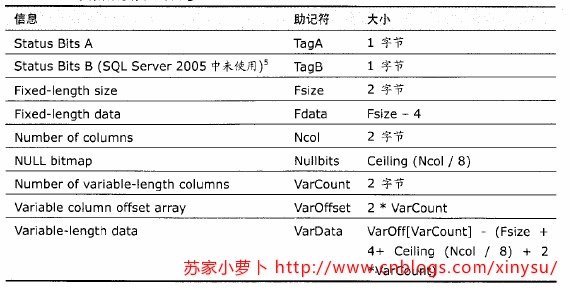
數據行在數據頁面的存儲結構詳見下表,分為幾個部分:基礎信息4字節、定長列相關、變長列相關及null位圖。詳見下表。這部分的內容具體參考《SQL server技術內幕:存儲引擎》第6章。 參考下圖,一行數據的大小是這麽計算的:Row_Size=Fixed_Data_Size+Variable_Data_Size+Null_Bitmap+4 。
各個部分其實都比較好理解,狀態B位未使用,狀態A位,詳細描述如下。
- 狀態位A:表示行屬性的位圖,1字節,8bit
-
- Bit 0 位,版本信息
- Bits 1-3 位,行記錄類型
-
- 0,primary record,主記錄
- 1,forwarded record
- 2,forwarding stub
- 3,index record,索引記錄
- 4,blob或者行溢出數據
- 5,ghost索引記錄
- 6,ghost數據記錄
- Bit 4 位,NULL位圖
- Bit 5 位,表示行中有變長列
- Bit 6 位,保留
- Bit 7 位,ghost record(幽靈記錄)
- 列偏移矩陣
-
- 如果一個表格,沒有變長列,那麽這個表格則不需要列偏移矩陣
- 一個變長列,有一個列偏移矩陣,一個列偏移矩陣2個字節,用於表示變長列中每個列的結束位置。
2.2 特殊情況(大對象、行溢出及forword)
2.2.1 大對象
text, ntext, image, nvarchar(max), varchar(max), varbinary(max), and xml這種數據列,稱為大對象列, 註意,變長數據類型nvarchar,varchar,varbinary只有當存儲內容大於8k才變為大對象列。 行不能跨頁,但是行的部分可以移出行所在的頁,因此行實際可能非常大。頁的單個行中的最大數據量和開銷是 8,060 字節 (8 KB)。考慮大對象列極為占用空間,所以在一行數據的主記錄中,是不存儲大對象列的,僅存儲 16字節 指向 大對象列實際存儲到LOB data頁面的位置。 比如,一個大對象列text,text列存儲5000的字符,其他列占用50個字符,如果是放在一起存儲的話,10行數據就需要10個page,掃描就需要10次IO;而如果不放在一次,一個IN-ROW-DATA page就能存儲這10行數據,text列單獨存放在 LOB data列,那麽,掃描這10行的主記錄,僅需要1次IO。所以,大對象列是不跟主記錄存儲在一起。 這樣,一個8k的數據頁,就能盡可能多的存儲主記錄,可以在查詢的時候,避免 大對象列占用主記錄空間,導致IO次數增增加。2.2.2 行溢出
超過 8,060 字節的行大小限制可能會影響性能,因為 SQL Server 仍保持每頁 8 KB 的限制。當合並 varchar、nvarchar、varbinary、sql_variant 或 CLR 用戶定義類型的列超過此限制時,SQL Server 數據庫引擎 將把最大寬度的記錄列移動到 ROW_OVERFLOW_DATA 分配單元的另一頁上,然後在主記錄記錄一個24字節的指針,用與描述 被移出的列 實際存儲位置。比如,一行數據總大小超過8k,那麽在insert的過程中,會把最大寬度的記錄移動到另外的數據頁面。 如果更新操作使記錄變長,大型記錄將被動態移動到另一頁。如果更新操作使記錄變短,記錄可能會移回 IN_ROW_DATA 分配單元中的原始頁。此外,執行查詢和其他選擇操作(例如,對包含行溢出數據的大型記錄進行排序或合並)將延長處理時間,因為這些記錄將同步處理,而不是異步處理。 一行數據(不包括大對象列)總長度超過了8k,則會把最大寬度的列內容移動到ROW_OVERFLOW_DATA頁面上,主記錄上留下一個24字節的指針 描述 被溢出挪走的列內容 實際存儲位置,這個稱為行溢出。2.2.3 forword
在一堆表內的一個數據頁面,存儲了N行數據,現在,其中一行數據的某一列發生修改,導致其列的長度加大,而剩余的頁面空間無法存儲該列數據,那麽這個時候,就會把該列數據移動到新的 IN_ROW_DATA 頁面上,在主記錄留下一個 9個字節的 指針,指向實際列的存儲位置,這個稱之為 forword。 forward的條件是:堆表、變長列、更新操作及其數據頁面剩余空間不足存儲新列內容。 為什麽一定要是堆表呢?因為如果是聚集索引表格,遇到這種情況,數據頁會split,把一半的內容另外存儲到新的數據頁,由於聚集索引上的非聚集索引鍵值查詢根據是主鍵,所以split操作不會影響到非聚集索引,但是堆表的非聚集索引結構查找行是根據RID,如果也split,那麽所有非聚集索引都需要修改鍵值RID,故在堆表上,使用了forword。 為什麽是更新操作呢?因為如果是INSERT操作,一開始就出現空間不足的情況,它老早就跑路到新的數據頁上了,不會再空間不足的數據頁面坐INSERT操作。 比如,一行數據原本存儲在一個數據頁面中,但是update某一列,增大其存儲內容,發現該數據頁沒有空閑的空間可以存儲該列內容,該列則會forword到另外的數據頁IN_ROW_DATA存儲,主記錄留下一個9字節的指針。3 測試存儲情況
測試思路- 先建立一個只有2列非空定長列的堆表,然後INSERT一行數據,檢查page頁面存儲內容
- 添加主鍵,檢查存儲頁面內容
- 增加一列:可空變長列
- 增加一列:非空變長列+默認值(分大對象和非大對象)
- 刪除無數據的列
- 刪除有數據的列
- 行溢出
- forword
3.1 堆表分析
create table tbrow(id int not null identity(1,1),name char(20) not null) insert into tbrow(name) select ‘xinysu‘; dbcc traceon(3604) dbcc ind(‘dbpage‘,‘tbrow‘,-1) --根據返回結果,判斷324為數據頁,如果不理解,請查看本系列第一篇博文 dbcc page(‘dbpage‘,1,324,3)

3.2 添加主鍵
alter table tbrow add constraint pk_tbrow primary key(id) dbcc traceon(3604) dbcc ind(‘dbpage‘,‘tbrow‘,-1)
可以看到,表格的IAM頁及數據頁全部都改變了,因為當一個堆表添加主鍵變為聚集索引表格的時候,需要重新組織數據頁,按照聚集索引的鍵值順序存儲,所以看到,整個數據頁存儲情況發生了變化。如果是一個大堆表添加聚集索引,那麽這是一個非常耗時及耗費IO、CPU的操作,並且會鎖表直到操作結束,需謹慎操作。
再次來分析現在的行記錄。
dbcc page(‘dbpage‘,1,311,3)
可以看到,數據行的內容並沒有發生變化,添加主鍵(聚集唯一索引),會重組整個表格的存儲順序,但是不會影響到行內的數據情況。
3.3 增加一列:可空變長列
alter table tbrow add constraint pk_tbrow primary key(id) dbcc traceon(3604) dbcc ind(‘dbpage‘,‘tbrow‘,-1) dbcc page(‘dbpage‘,1,311,3)
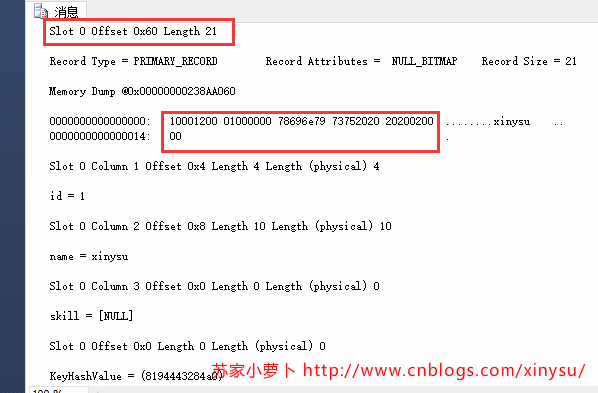
3.4 增加一列:非空變長列+默認值
3.4.1 非大對象列
alter table tbrow add task varchar(20) not null default ‘all A‘ ; dbcc traceon(3604) dbcc ind(‘dbpage‘,‘tbrow‘,-1) dbcc page(‘dbpage‘,1,311,3) 查看16進制的行記錄:10001200 01000000 78696e79 73752020 2020020000,發現與之前的是一樣的,查看表格內容,設置了NOT NULL帶默認值的列後,實際上,查詢出來 task列是有值存儲的,存儲內容為 ‘all A‘,但是查看16進制內容的時候,卻發現,這個數據頁內的行記錄存儲內容並沒有發生變化。
這是一個神奇的處理方式!為啥呢?
仔細查看page的解析內容,發現 :Slot 0 Column 4 Offset 0x0 Length 5 Length (physical) 0 。該列數據長度為5,但是,實際存儲長度為0,也就是這一列壓根沒有存儲在數據頁面中。
個人推測:當添加了NOT NULL列+默認值(非大對象列)的情況下,不對以往數據存儲記錄發生修改,但是在查詢的時候,會判斷該列是否有存儲數據,如果沒有則使用默認值顯示。 這樣有一個非常大的好處:節約存儲空間,不變更行記錄,DDL期間,無需對以往記錄做處理,僅需修改數據字典即可。
3.4.2 大對象列
alter table tbrow add descriptions text not null default ‘i love sql server‘ ;
dbcc traceon(3604)
dbcc ind(‘dbpage‘,‘tbrow‘,-1)
單薄的表格,一行的記錄,因為添加了大對象列,來了個 LOB data的IAM頁 以及 LOB data的數據頁 。不過,這次僅分析主記錄數據頁面pageid=311。
--主記錄數據頁面pageid=311
dbcc page(‘dbpage‘,1,311,3)
依舊來分析下這行存儲記錄,原先長度都是21,為啥添加了一個 text帶默認值的列,長度就增加為50bytes呢?
這裏註意兩個地方:原先的 task列跟 description列。task列之前是實際不存儲數據內容的,但是現在存儲了數據內容,description大對象列並沒有存儲數據在主記錄中,而是存儲在另外的lob data數據頁中,在主記錄僅存儲 描述 該列具體位置內容,占16bytes。
所以 該行記錄的長度=狀態A+狀態B+定長字段長度+定長字段內容+總列數+null位圖+變長列數量+列偏移矩陣+變長數據內容=1+1+2+(4+10)+2+1+2+2*3+(5+16)= 50 bytes。
來看看這個16進制的字符串:30001200 01000000 78696e79 73752020 20200500 0403001d 00220032 80616c6c 20410000 d1070000 00004b01 00000100 0000,詳細分析這行數據的存儲情況。先把這串字符按照字節數區分,詳細分析及推導見下圖。
由此可以得到幾個推論:大對象的列NOT NULL+默認值,是在數據頁上實際存儲默認值的,而且會對表格中的其他原本不存儲默認值的列造成影響,整個表格變成了把默認值實際存儲到數據頁面中去。當一個大表,需要增加一列大對象列NOT NULL+默認值時,會影響到表格裏面的每一行記錄,每行記錄都要增加一個16字節的來描述 大對象列的存儲位置,同時,原本不存儲默認值的列,也會實際存儲默認值到數據頁面中,這是一個鎖表久耗費IO的操作,對於一個大表來說。 是不是發現自己 添加一個大對象列+默認值是一件可怕的事情?如果真有這種需求,而且還是個大表,請謹慎考慮。
3.5 刪除無數據的列
--根據之前的查詢結果,skill這一列是沒有存儲數據的 alter table tbrow drop column skill dbcc traceon(3604) dbcc ind(‘dbpage‘,‘tbrow‘,-1) dbcc page(‘dbpage‘,1,311,3)
可以發現,刪除這一列,對實際數據存儲並沒有影響,但是該列會有一個標識值 DROPPED=[NULL]表明該列已被刪除,註意,這個表示只並不是存儲在每一行數據中,而是數據庫存儲引擎記錄。
截取數據頁面裏邊的16進制內容:30 00 1200 01000000 78696e79737520202020 0500 04 0300 1d0022003280 616c6c2041 0000d107000000004b01000001000000,發現與刪除前的是一樣的,對比如下:
/*
第一個行記錄為刪除前
第二個行記錄為刪除後
30 00 1200 01000000 78696e79737520202020 0500 04 0300 1d0022003280 616c6c2041 0000d107000000004b01000001000000
30 00 1200 01000000 78696e79737520202020 0500 04 0300 1d0022003280 616c6c2041 0000d107000000004b01000001000000
*/
得出結論:刪除一行無數據的列時,不需要修改行內數據存儲情況,僅需要修改涉及的數據字典跟刪除期間持有架構鎖,這是一個非常快的過程(但是如果表格一直被其他用戶進行操作,那麽申請架構鎖也會出現等待情況)。
3.6 刪除有數據的列
--根據之前的查詢結果,skill這一列是沒有存儲數據的 alter table tbrow drop column name dbcc traceon(3604) dbcc ind(‘dbpage‘,‘tbrow‘,-1) dbcc page(‘dbpage‘,1,311,3)
分析到這裏,可以發現,SQL SERVER在處理刪除列這一塊處理的非常巧妙,最大程度的減少了對表格可用性的影響,無論帶不帶數據,刪除的時候,只處理數據字典類相關內容,標識該列已被刪除,但是實際上沒有去到每一個頁面中去刪除數據,而是把這些列占用的空間在邏輯上修改為不存在,允許以後寫覆蓋。
作為一名小小的DBA,個人覺得在行數據的存儲結構這一塊,針對於增加列或者刪除列的處理,SQL SERVER 設計非常巧妙及高效!相對與 MySQL改進後的Online DDL,SQL SERVER將表格的可用性大大提高以及降低對系統資源的影響。(僅討論列的增加刪除DDL這一塊)
3.7 行溢出
行溢出這塊,不分析其16進制行記錄,著重在 行溢出的處理方式上。 #新表格測試 create table tbflow(id int not null ,cola varchar(6000),colb varchar(6000),colc varchar(6000)) INSERT INTO tbflow SELECT 1,replicate(‘1‘,1000),replicate(‘1‘,5000),replicate(‘1‘,3000) dbcc traceon(3604) dbcc ind(‘dbpage‘,‘tbflow‘,-1)
dbcc page(‘dbpage‘,1,334,3)
cola列1000個字符,colb列5000個字符,colc列3000個字符,不算其他字節使用,光著3列長度之和就大於8k,按照行溢出的處理,可以推測出 是colb 被移動到 Row-overflow data列,所以,先分析page 334 ,看主記錄的存儲情況,實際情況與推測一致。
3.8 Forword
Forword這塊,不分析其16進制行記錄,著重在Forword的處理方式上。 create table tbforword(id int not null ,cola varchar(6000),colb varchar(6000),colc varchar(6000)) insert into tbforword select 1,replicate(‘1‘,1000),replicate(‘1‘,500),replicate(‘1‘,500) insert into tbforword select 2,replicate(‘1‘,1000),replicate(‘1‘,500),replicate(‘1‘,500) insert into tbforword select 3,replicate(‘1‘,1000),replicate(‘1‘,500),replicate(‘1‘,500) dbcc traceon(3604) dbcc ind(‘dbpage‘,‘tbforword‘,-1) #記錄 IAM是385,主記錄是384頁 update tbforword set colb=replicate(‘1‘,4500) where id=2 dbcc traceon(3604) dbcc ind(‘dbpage‘,‘tbflow‘,-1)
pageid=384數據頁面中,存儲3行記錄大概用了6k+的空間,這時候,把id=2的colb列修改為4.5k長度,超過了一個頁面8k的範圍,也就意味著,這個被修改的列會被forword,根據新增的數據頁386,可推測出 forword的列存儲在386中。現在分析 pageid 384來驗證推測。詳見截圖,發現與推測一致。
dbcc page(‘dbpage‘,1,384,3)
4 行結構與DDL
SQL SERVER大話存儲結構(3)_數據行的行結構