
機器學習筆記(四)機器學習可行性分析
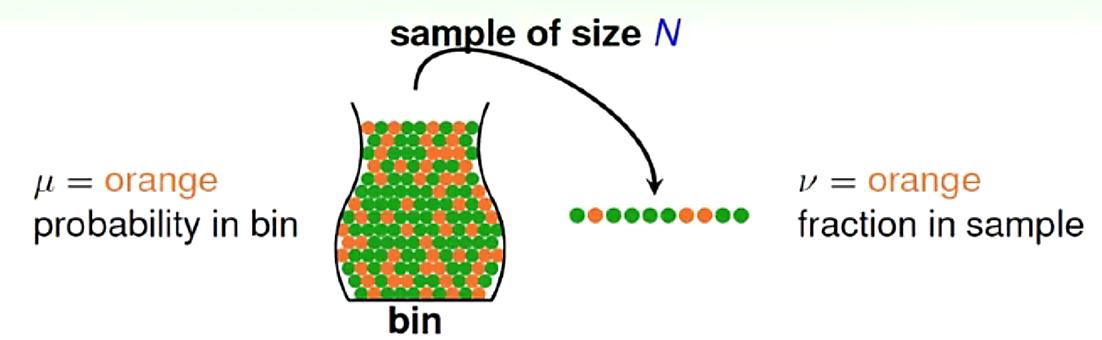
從大量數據中抽取出一些樣本,例如,從大量彈珠中隨機抽取出一些樣本,總的樣本中橘色彈珠的比例為 ,抽取出的樣本中橘色彈珠的比例為
,抽取出的樣本中橘色彈珠的比例為 ,這兩個比例的值相差很大的幾率很小,數學公式表示為:
,這兩個比例的值相差很大的幾率很小,數學公式表示為:
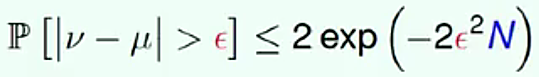
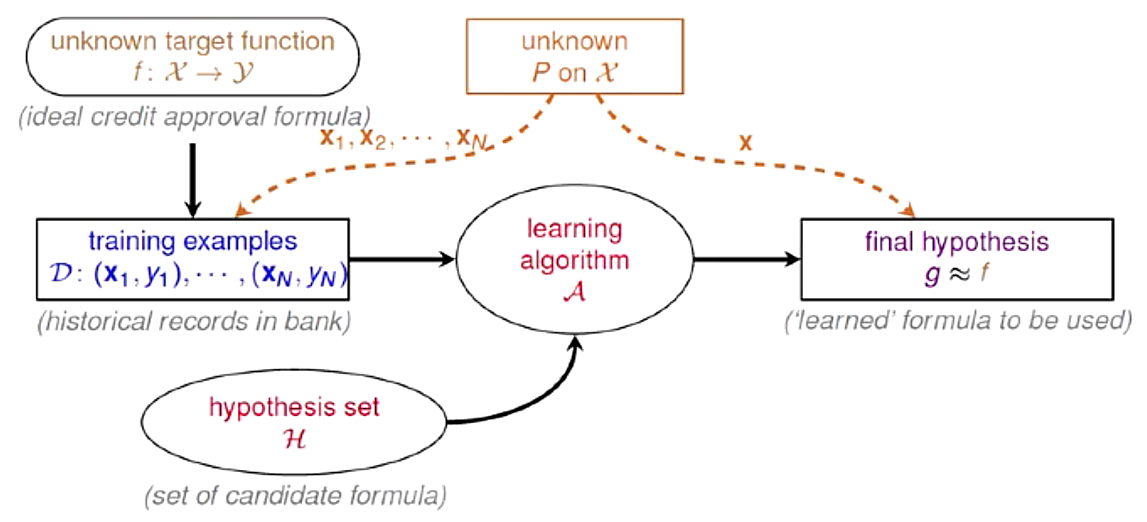
用抽取到的樣本作為訓練樣本集(in-sample),可以求得一個最佳的假設g,該假設最大可能的接近目標函數f,但是在訓練樣本集之外的其他樣本(out-of-sample)中,假設g和目標函數f可能差別很遠,不能說抽取樣本分布等同於所有樣本的分布,只是大致相近。
二者的錯誤幾率相差為:

當數據資料足夠多,且模型H集合有有限個的選擇,可以得到Ein和Eout是大致相等的
機器學習筆記(四)機器學習可行性分析
相關推薦
機器學習筆記(四)機器學習可行性分析
資料 表示 image 隨機 訓練樣本 -s mage 例如 lin 從大量數據中抽取出一些樣本,例如,從大量彈珠中隨機抽取出一些樣本,總的樣本中橘色彈珠的比例為,抽取出的樣本中橘色彈珠的比例為,這兩個比例的值相差很大的幾率很小,數學公式表示為: 用抽取到的樣本作為訓練
Live555學習筆記(四)—— RTP資料流向分析
void MultiFramedRTPSink ::afterGettingFrame1(unsigned frameSize, unsigned numTruncatedBytes, struct timeval presentationTime, unsigned durati
Python_sklearn機器學習庫學習筆記(四)decision_tree(決策樹)
min n) 空間 strong output epo from 標簽 ict # 決策樹 import pandas as pd from sklearn.tree import DecisionTreeClassifier from sklearn.
吳恩達機器學習學習筆記(四)(附作業程式碼註釋)
吳恩達機器學習學習筆記(四) 標籤: 機器學習 吳恩達機器學習學習筆記四 代價函式與反向傳播Costfunction and Backpropagation 一代價函式 1邏輯分類的評價函式
《自己動手寫java虛擬機器》學習筆記(四)-----搜尋class檔案(java)
專案地址:https://github.com/gongxianshengjiadexiaohuihui 首先是定義一個抽象類,把四種路徑的格式抽象出來 Entry.java package classpath; import java.io.IOException;
機器學習筆記(四)Logistic迴歸實現及正則化
一、Logistic迴歸實現 (一)特徵值較少的情況 1. 實驗資料 吳恩達《機器學習》第二課時作業提供資料1。判斷一個學生能否被一個大學錄取,給出的資料集為學生兩門課的成績和是否被錄取,通過這些資料來預測一個學生能否被錄取。 2. 分類結果評估 橫縱軸(特徵)為學生兩門課成績,可以在圖
機器學習筆記 (四)Scikit-learn CountVectorizer 與 TfidfVectorizer
Scikit-learn CountVectorizer 與 TfidfVectorizer 在文字分類問題中,我們通常進行特徵提取,這時,我們需要利用到要介紹的工具,或者其他工具。文字的特徵提取特別重要,體現這個系統做的好壞,分類的準確性,文字的特徵需要自己
吳恩達新書-機器學習學習筆記-(四)學習曲線
1.診斷偏差與方差:學習曲線 學習曲線可以將開發集的誤差與訓練集樣本的數量進行關聯比較。想要繪製出它,你需要設定不同大小的訓練集執行演算法。假設有1000個樣本,你可以選擇在規模為100、200、300、····1000的樣本集中分別執行演算法,接著便能得到開發集誤差隨訓練
機器學習(西瓜書)學習筆記(四)---------神經網路
1. 神經元模型 神經網路/人工神經網路:由具有適應性的簡單單元組成的廣泛並行互連的網路。 神經網路學習:機器學習和神經網路兩個學科交叉的部分。 Neural Networks中的基本單元:神經元。 從電腦科學的角度,NN就是一個包含了大量引數的數學模型,該模型由若干個函式相互代入而
機器學習筆記(四)——決策樹如何長成森林?
決策樹是一種基本的分類與迴歸方法,在整合方法中經常作為基礎分類器,比如說隨機森林演算法。決策樹模型具有可讀性和分類速度快兩大特點,但是也容易造成過擬合的問題。一般來說,決策樹演算法通常包括3個步驟: 特徵選擇、決策樹的生成和決策樹的修剪! 一、特徵選擇 當我們使用決策樹演算法對資料進
機器學習筆記(四)Logistic迴歸
我們都知道,如果預測值y是個連續的值,我們通常用迴歸的方法去預測,但如果預測值y是個離散的值,也就是所謂的分類問題,用線性迴歸肯定是不合理的,因為你預測的值沒有一個合理的解釋啊。比如對於二分類問題,我
機器學習筆記(四)——最大似然估計
一、最大似然估計的基本思想 最大似然估計的基本思想是:從樣本中隨機抽取n個樣本,而模型的引數估計量使得抽取的這n個樣本的觀測值的概率最大。最大似然估計是一個統計方法,它用來求一個樣本集的概率密度函式的引數。 二、似然估計 在講最小二乘法的時候,我們的例
google機器學習框架tensorflow學習筆記(四)
使用TensorFlow的基本步驟 tensorflow是一個可用於構建機器學習模型的平臺,但其實它的用途很廣泛。它是一種基於圖表的通用計算框架,可用來編寫你能想出的任何東西。事實上tensorflow.org的API頁面中提供了可在程式碼中使用的低階tensorflo
機器學習筆記(四)卷積神經網路CNN
1.前言: 卷積神經網路在計算視覺領域的表現十分出色,與普通的BP神經網路一樣,CNN同樣由神經元組成。其實卷積神經網路是卷積+神經網路,基本上由三部分組成:卷積層,pooling層,全連線層。 2.CNN:卷積層 卷積是一個訊號領域的概念,我們這裡提
《機器學習實戰》學習筆記(四)之Logistic(上)基礎理論及演算法推導、線性迴歸,梯度下降演算法
轉載請註明作者和出處:http://blog.csdn.net/john_bh/ 執行平臺: Windows Python版本: Python3.6 IDE: Sublime text3 一、概述 Logistic迴歸是統計學習中的經典
模式識別與機器學習筆記(二)機器學習的基礎理論
機器學習是一門對數學有很高要求的學科,在正式開始學習之前,我們需要掌握一定的數學理論,主要包括概率論、決策論、資訊理論。 一、極大似然估計(Maximam Likelihood Estimation,MLE ) 在瞭解極大似然估計之前,我們首先要明確什麼是似然函式(likelihoo
機器學習筆記(3)——使用聚類分析演算法對文字分類(分類數k未知)
聚類分析是一種無監督機器學習(訓練樣本的標記資訊是未知的)演算法,它的目標是將相似的物件歸到同一個簇中,將不相似的物件歸到不同的簇中。如果要使用聚類分析演算法對一堆文字分類,關鍵要解決這幾個問題: 如何衡量兩個物件是否相似 演算法的效能怎麼度量 如何確定分類的個數或聚類
周志華-機器學習-筆記(五)- 強化學習
#### 任務與獎賞 #### “強化學習”(reinforcement learning)可以講述為在任務過程中不斷摸索,然後總結出較好的完成任務策略。 強化學習任務通常用馬爾可夫決策過程(Markov Decision Process,簡稱M
機器學習筆記(七) 整合學習概述
整合學習(ensemble learning)是通過組合多個基分類器(baseclassifier)來完成學習任務。基分類器一般採用的是弱可學習分類器,通過整合學習,組合成一個強可學習分類器。 LeslieValiant提出了“強可學習(stron
機器學習筆記(1)監督學習和無監督學習
結果 關系 不同 情況 屬於 預測 數據 自己 復雜 監督學習 監督學習是指我們給予算法一個數據集,這個數據集可以是以往相同類型問題的結果,或者絕對正確的經驗答案的集合,也就是統計中常說的樣本,並且這些數據都是有其固有的“正確答案”,然後算法根據這個集合做出對當前相同類型的