
機器學習公開課筆記第九周之大數據梯度下降算法
一,隨機梯度下降法(Stochastic Gradient Descent)
當訓練集很大且使用普通梯度下降法(Batch Gradient Descent)時,因為每一次\(\theta\)的更新,計算微分項時把訓練集的所有數據都叠代一遍,所以速度會很慢

批量梯度下降法是一次性向計算m組數據的微分,一次更新\(\theta\),計算m組數據的微分時,用的是同一個\(\theta\),會獲得全局最小值
隨機梯度下降法依次計算亂序的m組數據的微分,m次更新\(\theta\),計算m組數據的微分時,用的是上一組數組更新完的\(\theta\),會獲得非常接近於全局最小值的局部最小值
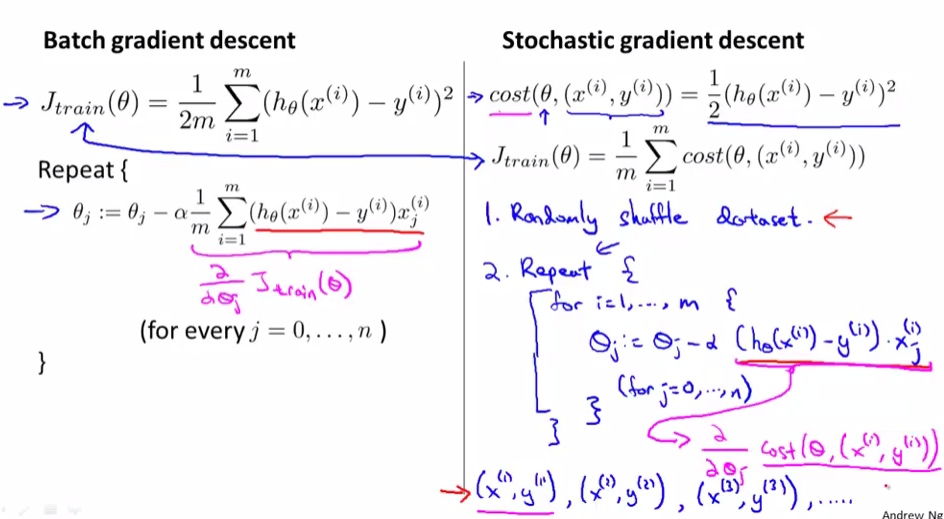
一般叠代1-10次

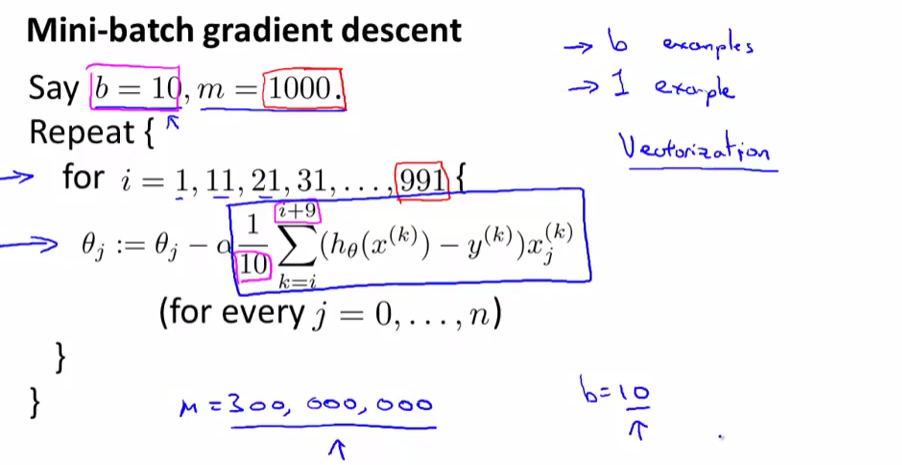
二,小批量梯度下降法(Mini-Batch Gradient Descent)
三種梯度下降法對比

小批量梯度下降法就是一次更新b(一般是10,2~100d都可以)組數據,更新\( \lceil \frac{m}{b} \rceil\),介於隨機梯度下降法和批量梯度下降法之間
小批量梯度下降法比隨機梯度下降法速度快是因為更新\(\theta\)的頻率快,比隨機梯度下降法快是因為計算微分的時候可以向量化運算加速(即矩陣相乘)
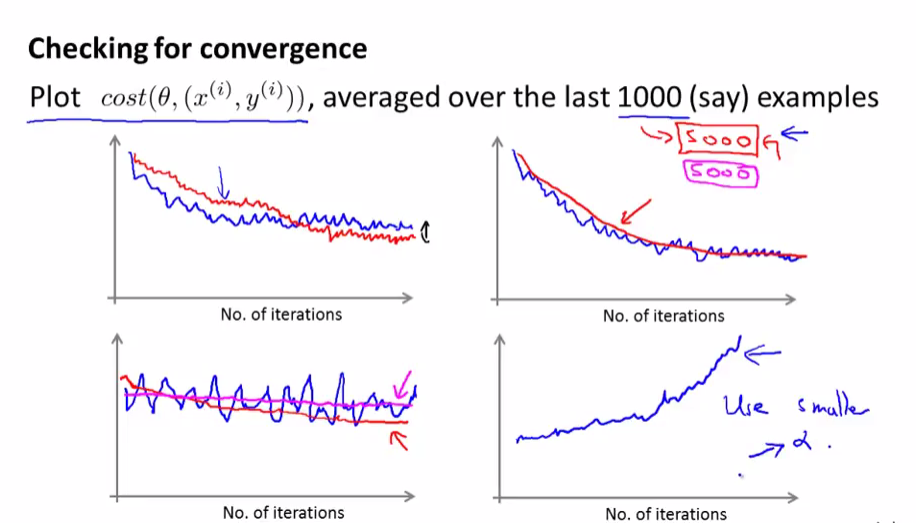
三,驗證代價函數收斂
在每次更新\(\theta\)前先計算\(Cost(\theta, (x^{(i)}, y^{(i)}))\)
因為隨機梯度下降法每次更新\(\theta\),並不能保證代價函數\(Cost(\theta, (x^{(i)}, y^{(i)}))\)變小,只能保證總體震蕩上變小,所以我們只需最近1000個數據\(Cost(\theta, (x^{(i)}, y^{(i)}))\)的平均值

上面兩副圖是比較正常的隨機梯度下降圖,下左需要提高樣例數(1000->5000)再看看是否收斂,下右明顯單調遞增,選擇更小的學習速率\(\alpha\)或者更改特征試試
我們還可以動態修改學習速率來使代價函數收斂,隨著叠代次數增加而減少
\(\alpha = \frac{const1}{iterationNumber + const2}\)

四,在線學習
在線學習就是在沒有預先準備好的數據集的情況下,有數據流實時給予學習模型,實時更新\(\theta\),優點
1,不需要保存大量本地數據
2,實時根據數據的特征更改\(\theta\)
其實和隨機梯度下降法類似

在線學習其他例子,可以根據用戶搜索的關鍵詞特征,來實時學習反饋結果,在根據用戶的點擊來更新\(\theta\),如

機器學習公開課筆記第九周之大數據梯度下降算法