
java利用itext填寫pdf模板並匯出
1.先用word做出介面
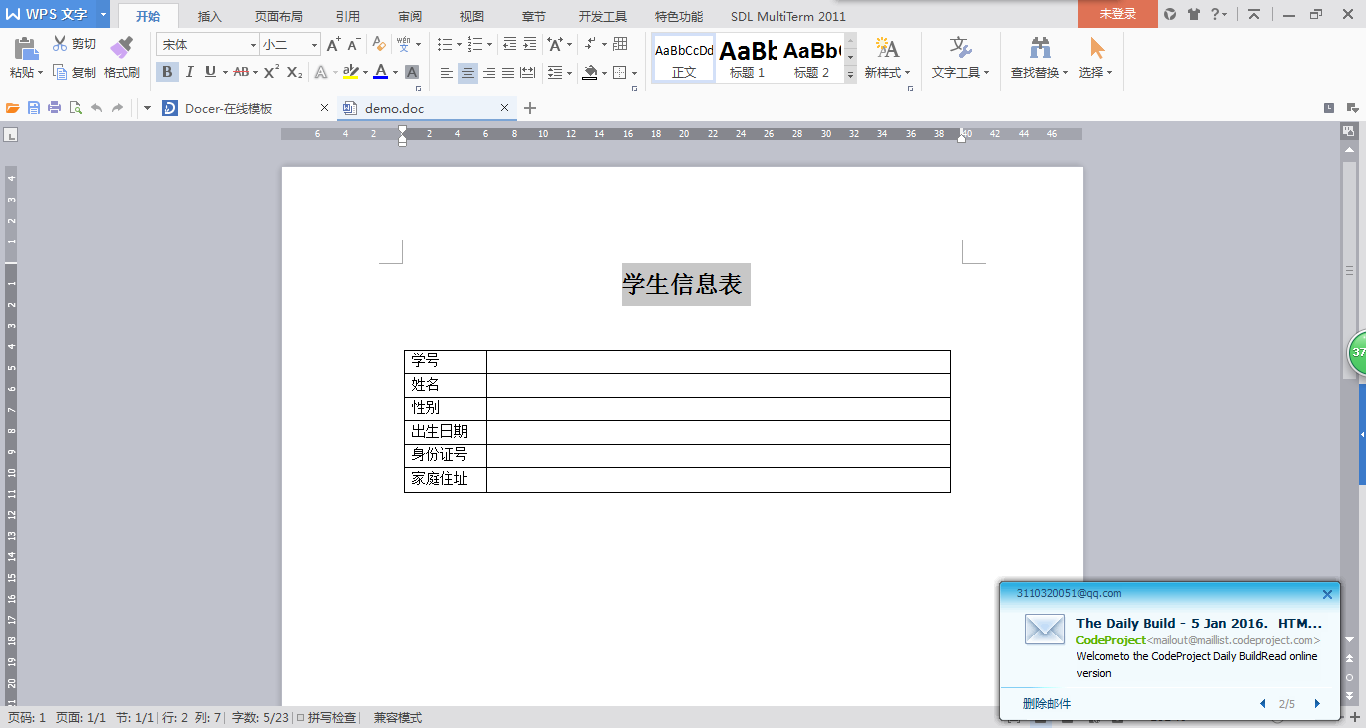{kind=link}
2.再轉換成pdf格式
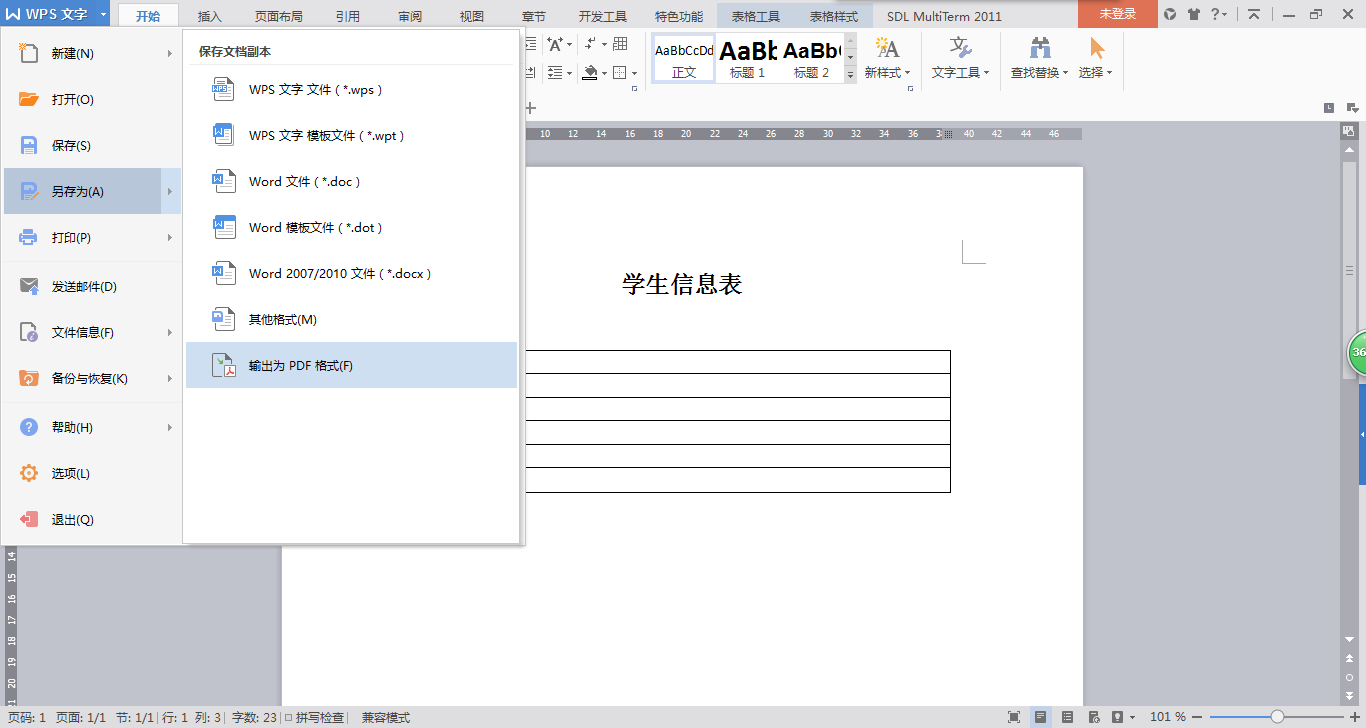{kind=link}
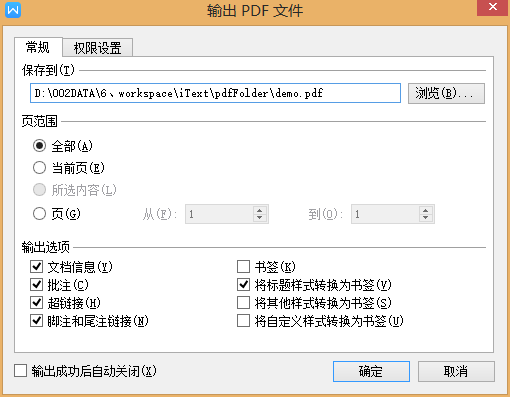{kind=link}
3.用Adobe Acrobat 開啟你剛剛用word轉換成的pdf
{kind=link}
會出現如下介面
{kind=link}
下一步
{kind=link}
點選瀏覽,選擇剛才你轉換好的pdf
{kind=link}
下一步
4.開啟後它會自動偵測並命名錶單域,右鍵表單域,點選屬性,出現文字域屬性對話方塊,有的人說要改成中文字型,可是我沒有改一樣成功啦
{kind=link}
5.一般情況下不需要修改什麼東西,至少我沒有修改哦
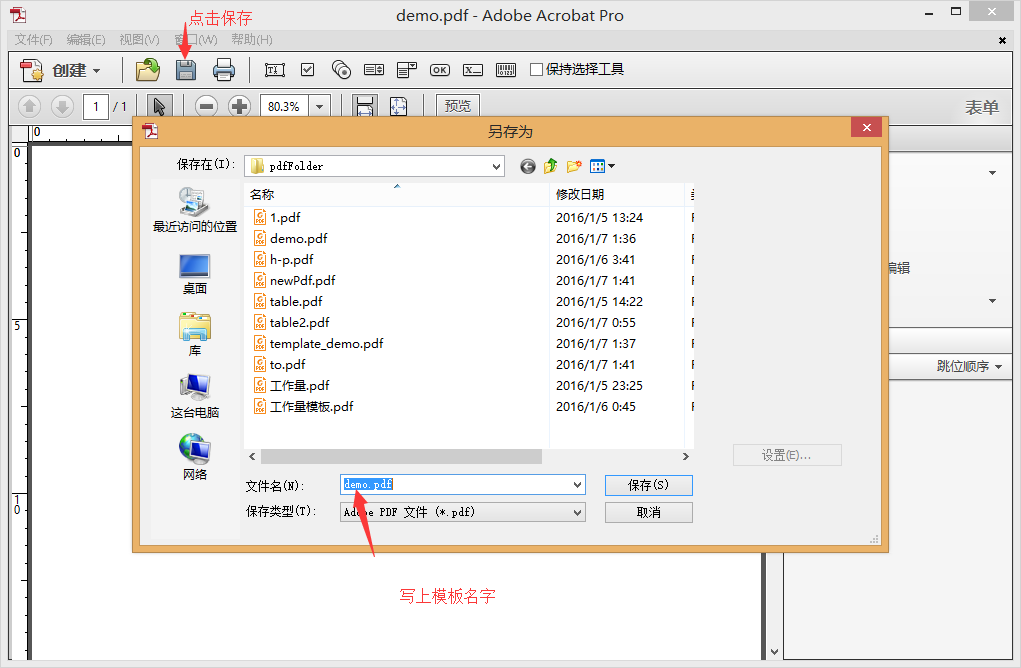{kind=link}
6.直接另存為就行了
************************上程式********************************
準備:itext的jar包包:官網:http://sourceforge.net/projects/itext/files/
因為是利用模板,所以不需要建立字型來解決中文不顯示的問題
public void fillTemplate(){//利用模板生成pdf //模板路徑 String templatePath = "pdfFolder/template_demo.pdf"; //生成的新檔案路徑 String newPDFPath = "pdfFolder/newPdf.pdf"; PdfReader reader; FileOutputStream out; ByteArrayOutputStream bos; PdfStamper stamper;try { out = new FileOutputStream(newPDFPath);//輸出流 reader = new PdfReader(templatePath);//讀取pdf模板 bos = new ByteArrayOutputStream(); stamper = new PdfStamper(reader, bos); AcroFields form = stamper.getAcroFields(); String[] str= {"123456789","小魯","男","1994-00-00", "130222111133338888" ,"河北省唐山市"}; int i = 0; java.util.Iterator<String> it = form.getFields().keySet().iterator(); while(it.hasNext()){ String name = it.next().toString(); System.out.println(name); form.setField(name, str[i++]); } stamper.setFormFlattening(true);//如果為false那麼生成的PDF檔案還能編輯,一定要設為true stamper.close(); Document doc = new Document(); PdfCopy copy = new PdfCopy(doc, out); doc.open(); PdfImportedPage importPage = copy.getImportedPage( new PdfReader(bos.toByteArray()), 1); copy.addPage(importPage); doc.close(); } catch (IOException e) { System.out.println(1); } catch (DocumentException e) { System.out.println(2); } }
模板如圖:
{kind=link}
程式結果如圖:
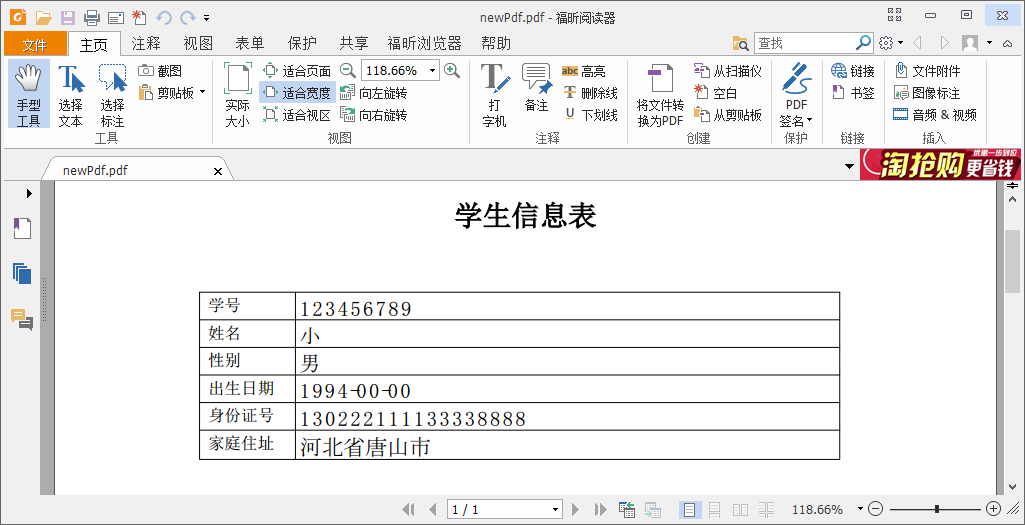{kind=link}
可以看到,少了一個魯......於是我把模板的表單域的字型改成了宋體,結果中文一個也不顯示了,所以我判斷是他那個字型支援的中文比較少吧,先不管這個了
現在都兩點多了(不是下午兩點多啊。。。)
到此時,利用模板生成pdf已經over了,我再說說入門的hello word 級別的程式吧,反正閒著也是閒著
程式一:
public void test1(){//生成pdf Document document = new Document(); try { PdfWriter.getInstance(document, new FileOutputStream("pdfFolder/1.pdf")); document.open(); document.add(new Paragraph("hello word")); document.close(); } catch (FileNotFoundException | DocumentException e) { System.out.println("file create exception"); } }
結果:
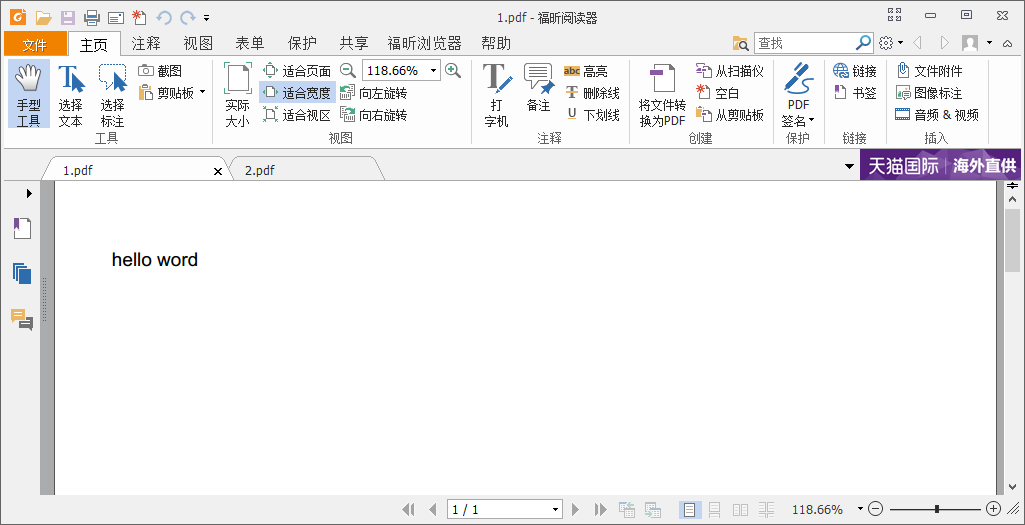{kind=link}
可是如果要輸出中文呢,上面這個就不行了,就要用到語言包了
最新亞洲語言包:http://sourceforge.net/projects/itext/files/extrajars/
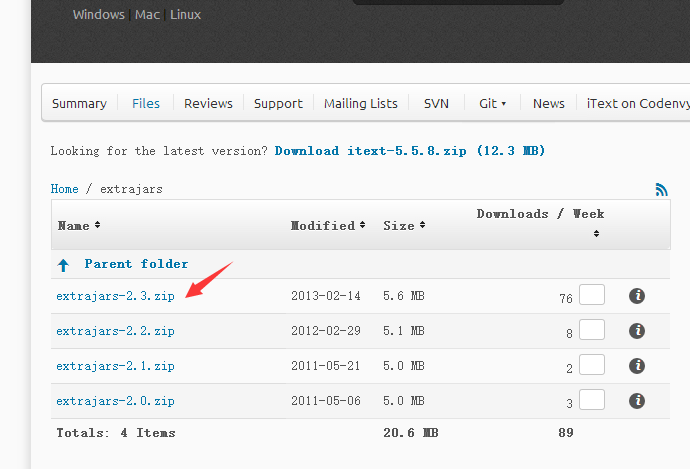{kind=link}
public void test1_1(){ BaseFont bf; Font font = null; try { bf = BaseFont.createFont( "STSong-Light", "UniGB-UCS2-H", BaseFont.NOT_EMBEDDED);//建立字型 font = new Font(bf,12);//使用字型 } catch (DocumentException | IOException e) { e.printStackTrace(); } Document document = new Document(); try { PdfWriter.getInstance(document, new FileOutputStream("pdfFolder/2.pdf")); document.open(); document.add(new Paragraph("hello word 你好 世界",font));//引用字型 document.close(); } catch (FileNotFoundException | DocumentException e) { System.out.println("file create exception"); } }
結果如下:
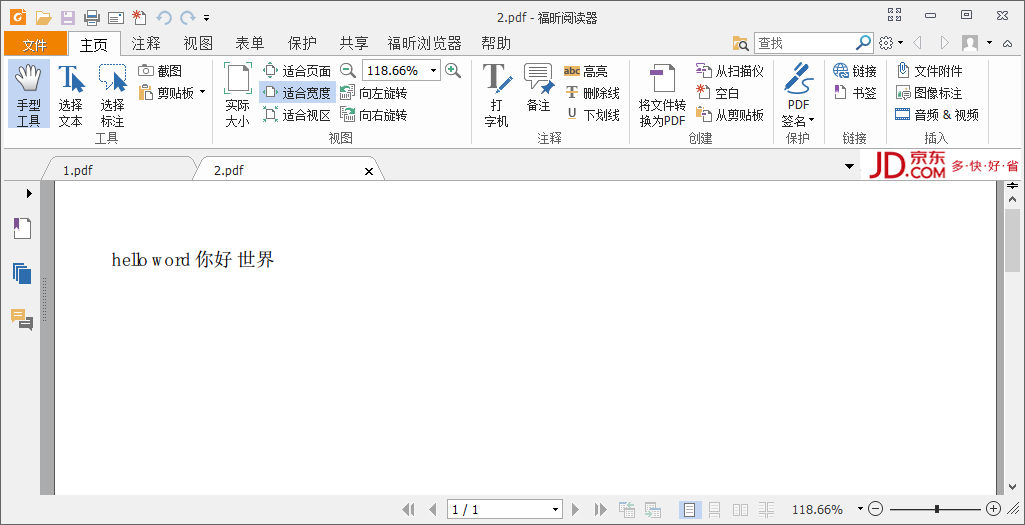{kind=link}
另外一種方法:我不用第三方語言包:
我是在工程目錄裡面新建了一個字型資料夾Font,然後把宋體的字型檔案拷貝到這個資料夾裡面了
上程式:
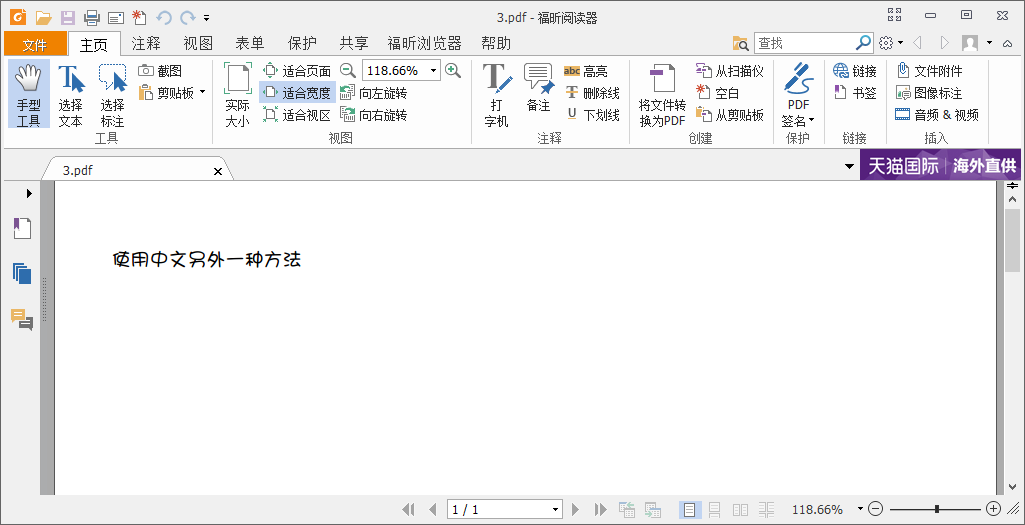
public void test1_2(){ BaseFont bf; Font font = null; try { bf = BaseFont.createFont("Font/simsun.ttc,1", //注意這裡有一個,1 BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED); font = new Font(bf,12); } catch (DocumentException | IOException e) { e.printStackTrace(); } Document document = new Document(); try { PdfWriter.getInstance(document, new FileOutputStream("pdfFolder/3.pdf")); document.open(); document.add(new Paragraph("使用中文另外一種方法",font)); document.close(); } catch (FileNotFoundException | DocumentException e) { System.out.println("file create exception"); } }
{kind=link}
我如果換成:華康少女文字W5(P).TTC,即
bf = BaseFont.createFont("Font/華康少女文字W5(P).TTC,1", //simsun.ttc
BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);
{kind=link}