
C#簡單爬取資料(.NET使用HTML解析器NSoup和正則兩種方式匹配資料)
一、獲取資料
想弄一個數據庫,由於需要一些人名,所以就去百度一下,然後發現了360圖書館中有很多人名
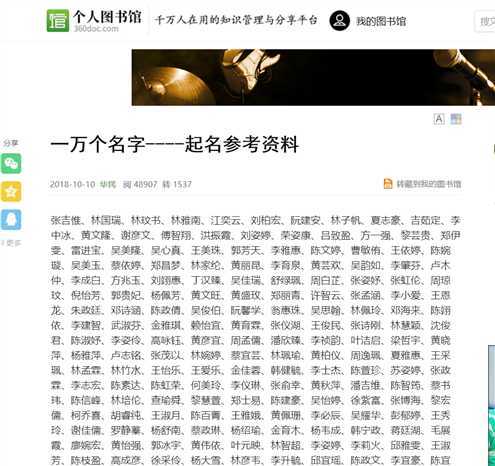
然後就像去複製一下,發現複製不了,需要登陸
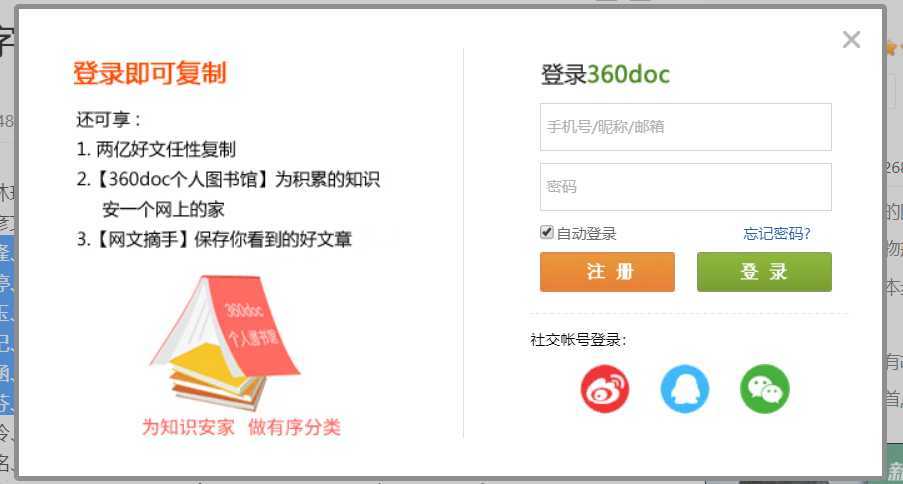

此時f12檢視原始碼是可以複製的,不過就算可以複製想要插入資料也是很麻煩的。既然複製走不通,於是我抱著探索知識的精神,打開了Visual Studio
首先我們需要先拿到整個頁面的資料,此時的話可以使用WebClient物件來獲取資料(HttpWebRequest方式稍微有點麻煩),然後使用byte陣列來接受一下返回值
public static void GetData(String address)
{
WebClient wc = new WebClient();
byte[] htmlData = wc.DownloadData(address);
}
此時需要將htmlData物件解碼為String物件,然後我們在網站中f12看一下解碼方式

可以看到charset=utf-8,說明需要用utf-8來解碼,然後使用Encoding物件來解碼
string html = Encoding.UTF8.GetString(htmlData);
我們輸出一下html有沒有值

static void Main(string[] args)
{
//將地址複製過來
GetData("http://www.360doc.com/content/18/1010/13/642066_793541226.shtml");
Console.ReadKey();
}
public static void GetData(String address)
{
WebClient wc = new WebClient();
//地址由呼叫時傳入
byte[] htmlData = wc.DownloadData(address);
string html = Encoding.UTF8.GetString(htmlData);
Console.WriteLine(html);
}
輸出:

二、Regex匹配
接下來就是匹配的問題了,首先看一下html文件的結構
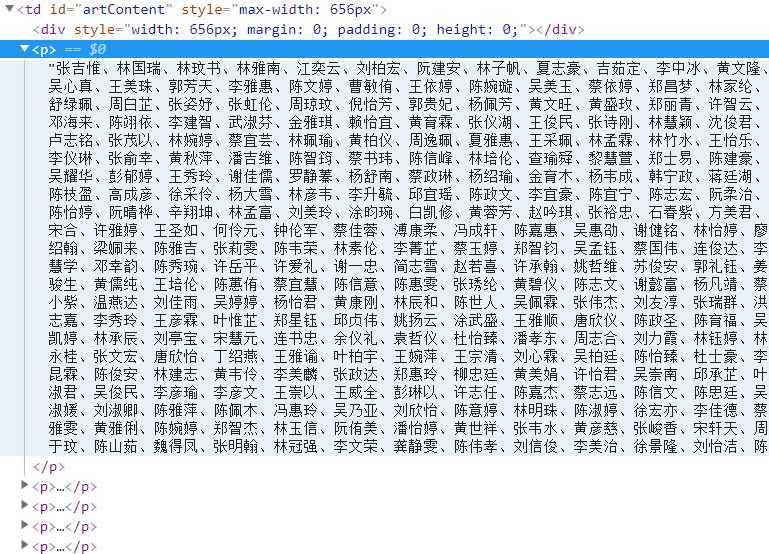
就是說只需要匹配到所有的p標籤,然後拿到其中的內容就行了
第一種想到的就是使用正則表示式匹配:
public static void GetData(String address)
{
WebClient wc = new WebClient();
//地址由呼叫時傳入
byte[] htmlData = wc.DownloadData(address);
string html = Encoding.UTF8.GetString(htmlData);
//使用正則表示式匹配 <p或P>非空字元至少100個<P或p>
Regex reg = new Regex("<[pP]>\\S{100,}</[Pp]>");
//接受所有匹配到的項
MatchCollection result = reg.Matches(html);
//迴圈輸出
foreach (Match item in result)
{
Console.WriteLine(item.Value);
}
}
呼叫不變,啟動:

匹配到是匹配到了,但是我們把<p></p>標籤也匹配出來了,所以把正則表示式改進一下,使用組匹配,將p標籤中的內容單獨匹配出來(當然也可以擷取字串)。也就是說在寫正則表示式時,將想要單獨匹配出來的資料用括號"(想要單獨匹配出來的資料)"括起來,來看一下怎麼寫:
Regex reg = new Regex("<[pP]>(\\S{100,})</[Pp]>");
然後如果想要拿資料的話,需要使用Match物件的Groups屬性通過索引來獲取匹配到的組:
public static void GetData(String address)
{
WebClient wc = new WebClient();
//地址由呼叫時傳入
byte[] htmlData = wc.DownloadData(address);
string html = Encoding.UTF8.GetString(htmlData);
//使用正則表示式組匹配 <p或P>(非空字元至少100個)<P或p>
Regex reg = new Regex("<[pP]>(\\S{100,})</[Pp]>");
//接受所有匹配到的項
MatchCollection result = reg.Matches(html);
//迴圈輸出
foreach (Match item in result)
{
//0的話是整體匹配到的字串物件
//1就是第一個匹配到的組(\\S{100,)
Console.WriteLine(item.Groups[1]);
}
}
輸出結果:

這次p標籤就沒有被匹配進入組中(如果通過item.Groups[0]拿到的回是和上面匹配到一樣的資料,會帶p標籤)
匹配到了之後就可以使用item.Groups[1].Split(‘、‘)來將字串分割為String陣列,然後迴圈寫入資料庫,或者進行其他操作。
三、HTML解析器NSoup
雖然正則表示式也可以匹配,但是如果對正則表示式比較陌生的話,可能就不是友好了。如果有方法可以像用js操作html元素一樣,用C#操作html字串,就非常棒了。NSoup就是可以做到解析html字串,變成可操作的物件。
首先使用前先在管理NuGet程式包中新增:NSoup,直接就可以搜尋到,新增完成之後接下來就看一下如何使用
使用NSoupClient.Parse(放入html程式碼:<html>....</html>)建立一個宣告Docuemnt文件物件:
//宣告Document物件
Document doc = NSoupClient.Parse(html);
第二種就是使用Document doc = NSoupClient.Connect(放入url) .Get()/.Post(),然後他就會自動獲取url地址的html程式碼,並且根據html程式碼載入一個Document物件
//通過url自動載入Document物件
Document doc = NSoupClient.Connect(address).Get();
當然還有其他方式獲取,然後我們看一下如何使用Document物件
//通過id獲取元素
//獲取id為form的元素
Element form = doc.GetElementById("form");
//通過標籤名獲取元素
//獲取所有的p標籤
Elements p = doc.GetElementsByTag("p");
//通過類樣式獲取元素
//獲取類樣式為btn的元素
Elements c = doc.GetElementsByClass("btn");
//通過屬性獲取
//獲取包含style屬性的元素
Elements attr = doc.GetElementsByAttribute("style");
也可以自己組合一些其他的巢狀操作,例如:
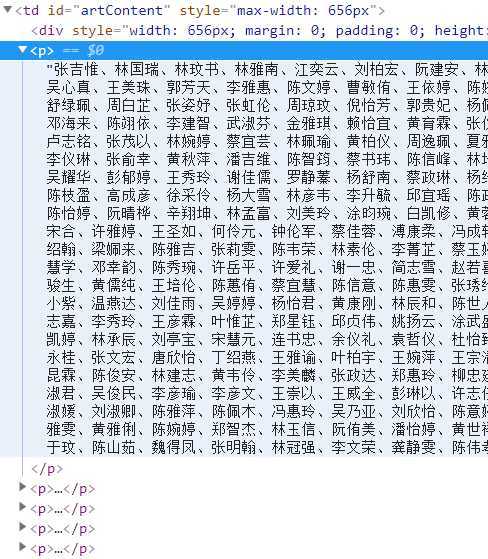
獲取id為artContent下的所有p標籤
//使用鏈式程式設計
//獲取id為artContent下的所有p標籤
Elements ps = doc.GetElementById("artContent").GetElementsByTag("p");
//等同於
//Element artContent = doc.GetElementById("artContent");
//Elements ps = artContent.GetElementsByTag("p");
元素方法的使用:
//Elements是Element元素的集合 多了個s
//Element物件的方法
Element id = doc.GetElementById("id");
//獲取或設定id元素的文字
id.Text();
//獲取或設定id元素的html程式碼
id.Html();
//獲取或設定id元素的value值
id.Val();
都是像js操作html元素一樣的方法,而且方法的名字也很人性,基本上一看就會知道方法是什麼意思,方法也太多了就不一一講了。
然後我們來使用NSoup獲取所有的名字,來試一下就會發現很簡單了:
方式一:
public static void GetData(String address)
{
WebClient wc = new WebClient();
byte[] htmlData = wc.DownloadData(address);
string html = Encoding.UTF8.GetString(htmlData);
Document doc = NSoupClient.Parse(html);
//先獲取id為artContent的元素,再獲取所有的p標籤
Elements p = doc.GetElementById("artContent").GetElementsByTag("p");
foreach (Element item in p)
{
Console.WriteLine(item.Text());
}
}
方式二:
public static void GetData(String address)
{
//直接通過url來獲取Document物件
Document doc = NSoupClient.Connect(address).Get();
//先獲取id為artContent的元素,再獲取所有的p標籤
Elements p = doc.GetElementById("artContent").GetElementsByTag("p");
foreach (Element item in p)
{
Console.WriteLine(item.Text());
}
}
執行結果都是一樣的
