
python 信用卡欺詐模型建立
阿新 • • 發佈:2019-02-10
一.資料準備
來源於Kaggle
資料集包含歐洲持卡人於2013年9月通過信用卡進行的交易。該資料集提供兩天內發生的交易,其中在284,807筆交易中有492起欺詐行為。資料集非常不平衡,負面類別(欺詐)佔所有交易的0.172%。
它只包含數值輸入變數,這是PCA變換的結果。不幸的是,由於保密問題,我們無法提供有關資料的原始特徵和更多背景資訊。特徵V1,V2,... V28是用PCA獲得的主要元件,唯一沒有用PCA轉換的特徵是'Time'和'Amount'。
- “時間”包含每個事務與資料集中第一個事務之間經過的秒數。
- '金額'是交易金額,該特徵可以用於依賴於例子的成本敏感性學習。
- “Class”是響應變數,在欺詐的情況下其值為1,否則為0。
二.準備並初步檢視資料集
執行 import matplotlib.pyplot as plt
返回錯誤資訊:。。。
ModuleNotFoundError: No module named 'tkinter'
# coding:utf-8 # 準備並初步檢視資料集 import numpy as np import pandas as pd import matplotlib.pyplot as plt import matplotlib.gridspec as gridspec import seaborn as sns import sklearn from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split # utils是utilities的縮寫。意思是小工具 from sklearn.utils import shuffle from sklearn.metrics import confusion_matrix # 該模組實現資料嵌入技術 from sklearn.manifold import TSNE # pass語句表示什麼都不做,避免不符合語法 pass # 匯入並檢視資料 creditcard_data = pd.read_csv('creditcard.csv') # 檢視資料框基本資訊,如特徵、各特徵條數、格式。。注意info和info()的區別 # info是檢視完整內容,而info()是特徵、各特徵條數、格式 creditcard_data.info() # 檢視各列統計資訊 creditcard_data.describe() # pass不執行 pass # 看看欺詐與正常各自的條數統計 count_classes = creditcard_data.Class.value_counts() # 用一張條形圖直觀的觀察欺詐和非欺詐的數量和比例 count_classes.plot(kind='bar')
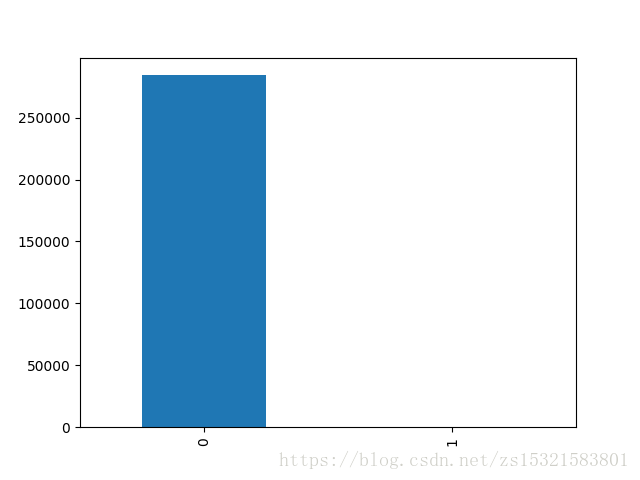
可以看到,此資料集存在嚴重的資料不平衡的問題!
三 時間序列下的交易發生頻率(分為詐騙和正常)
# 圖表展示時間序列中欺詐和正常事件的頻率 # bins直方圖(hist)引數,表示在整個連續區間內的分割槽數,直方圖的作用:分段頻率統計 bins = 50 # 出現問題:如何指派給誰畫圖?!預設情況下,是先給最後一個圖畫圖 # 在ax1中繪製直方圖。 plt.subplot(2, 1, 1) plt.hist(creditcard_data.Time[creditcard_data.Class == 1], bins=50) plt.title('fraud') plt.ylabel('transaction numbers') plt.subplot(212) plt.hist(creditcard_data.Time[creditcard_data.Class == 0], bins=bins) plt.title('normal') plt.subplots_adjust(wspace =0, hspace =0.5)#調整子圖間距
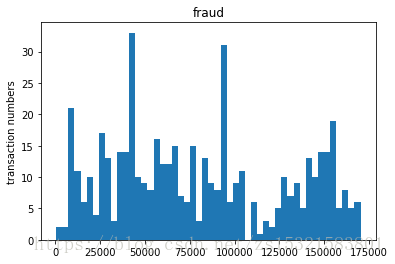
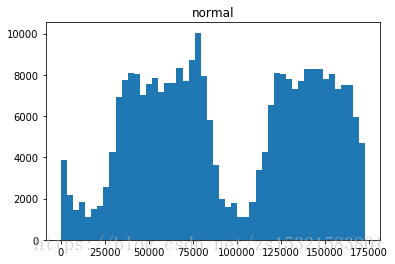
- 欺詐與時間並沒有必然聯絡,不存在週期性;
- 正常交易有明顯的週期性,有類似雙峰這樣的趨勢。
四 詐騙和正常交易交易金額的頻率分佈
# 圖表展示不同交易額段內的頻率(分別展示詐騙和正常)
plt.subplot(211)
plt.hist(creditcard_data.Amount[creditcard_data.Class == 1], bins=30)
plt.title('fraud')
plt.subplot(212)
plt.hist(creditcard_data.Amount[creditcard_data.Class == 0], bins=30)
plt.title('normal')
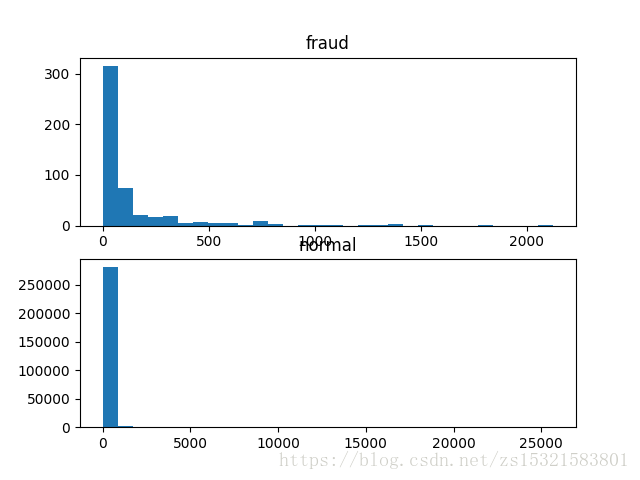
五 各特徵和因變數的關係:
# 自變數V1~V29與因變數的關係
# 獲取自變數特徵列表
features = [x for x in creditcard_data.columns
if x not in ['Time', 'Amount', 'Class']]
plt.figure(figsize=(12, 28*4))
# 隱式指定網格行數列數(隱式指定子圖行列數)
gs = gridspec.GridSpec(28, 1)
for i, cn in enumerate(features):
# 在第幾個子圖中繪製圖表/plt.subplot()中的是子圖的位置
ax = plt.subplot(gs[i])
sns.distplot(creditcard_data[cn][creditcard_data.Class == 1], bins=50, color='red')
sns.distplot(creditcard_data[cn][creditcard_data.Class == 0], bins=50, color='green')
ax.set_title(str(cn))
plt.subplots_adjust(wspace =0, hspace =0.5)#調整子圖間距
plt.savefig('各個變數與class的關係.png', transparent=False, bbox_inches='tight')各特徵和因變數的關係用核密度估計圖表示出來,可以看出:
1.同一個特徵欺詐和正常的區分度是如何,區分度越高,說明這個特徵對結果影響越大
2.不同特徵之間欺詐和正常的區分度比較

六 用邏輯迴歸方法對信用卡資料進行建模分析
為什麼用邏輯迴歸:
1.二分類問題
2.特徵值全部是數值型別
輸入模型的資料準備
# 先把資料分為欺詐和正常組,然後按比例生產訓練和測試資料集
# 分組
fraud = creditcard_data[creditcard_data.Class == 1]
normal = creditcard_data[creditcard_data.Class == 0]
# 訓練特徵集
# 取欺詐資料集中的一部分比例的樣本,樣本是經過打亂的
x_train = fraud.sample(frac=0.7)
# 將欺詐資料取出0.7,將正常資料取出0.7,然後合併成訓練集
x_train = pd.concat([x_train, normal.sample(frac=0.7)])
# 測試集
# 去除掉訓練集中的資料條剩下的就是測試集資料條
x_test = creditcard_data.loc[~creditcard_data.index.isin(x_train.index)]
# 標籤集
y_train = x_train.Class
y_test = x_test.Class
# 去掉特徵集裡的標籤和時間列
x_train = x_train.drop(['Class', 'Time'], axis=1)
x_test = x_test.drop(['Class', 'Time'], axis=1)
# 檢視資料結構
print(x_train.shape, y_train.shape, '\n', x_test.shape, y_test.shape)
建立邏輯迴歸模型,用測試集進行模型預測,並且通過幾種內建方法來評價預測結果的水平。
混淆矩陣:用來評價分類結果好壞的一個表單。
my_confusion_matrix()函式:
主要是針對預測出來的結果,和原來的結果對比,算出混淆矩陣,不必自己計算。其對每個類別的混淆矩陣都計算出來了,並且labels引數預設是排序了的。
my_classification_report()函式:
主要通過sklearn.metrics函式中的classification_report()函式,針對每個類別給出詳細的準確率、召回率和F-值這三個引數和巨集平均值,用來評價演算法好壞。
# 建立邏輯迴歸模型
from sklearn import metrics
import scipy.optimize as op
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold, cross_val_score
from sklearn.metrics import (precision_recall_curve,
auc, roc_auc_score,
roc_curve, recall_score,
classification_report)
lrmodel = LogisticRegression()
lrmodel.fit(x_train, y_train)
# 檢視模型
print(lrmodel)
# 檢視混淆矩陣(混淆矩陣是用來評價分類好壞的表單):metrics.confusion_matrix(true,[[
# predicted)
ypred_lr = lrmodel.predict(x_test)
print(metrics.confusion_matrix(y_test, ypred_lr))
# 檢視分類報告
print(metrics.classification_report(y_test, ypred_lr))
# 檢視預測精度與決策覆蓋面
print('Accuracy:%f'%(metrics.accuracy_score(y_test,ypred_lr)))
print('Area under the curve:%f'%(metrics.roc_auc_score(y_test,ypred_lr)))