
MySQL:記錄的增刪改查、單表查詢、約束條件、多表查詢、連表、子查詢、pymysql模組、MySQL內建功能
資料操作
插入資料(記錄): 用insert;
補充:插入查詢結果: insert into 表名(欄位1,欄位2,...欄位n) select (欄位1,欄位2,...欄位n) where ...;
更新資料update
語法: update 表名 set 欄位1=值1,欄位2=值2 where condition;
刪除資料delete:delete from 表名 where condition;
查詢資料select:
單表查詢:
語法:

select distinct 欄位1,欄位2... from 表名 where 條件 group by field having 篩選 order by field limit 限制條數;
關鍵字的執行優先順序:
from where group by having select distinct order by limit # 1.找到表:from # 2.通過where指定的約束條件,去檔案/表中取出一條條記錄 # 3.將取出的一條條記錄程序分組 group by,如果沒有group by,則整體作為一組 # 4.將分組的結果進行having過濾 # 5.執行 select # 6.去重 # 7.將結果按順序排序:order by # 8.限制結果的顯示條數
簡單查詢:
#建立表
create table employee(
id int not null unique auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male', # 大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int,
depart_id int
);
#插入記錄
#三個部門:教學,銷售,運營
insert into employee(name,sex,age,hire_date,post,salary,office,depart_id) values
('egon','male',18,'20170301','老男孩駐沙河辦事處外交大使',7300.33,401,1),
('alex','male',78,'20150302','teacher',1000000.31,401,1),
('wupeiqi','male',81,'20130305','teacher',8300,401,1),
('yuanhao','male',73,'20140701','teacher',3500,401,1),
('liwenzhou','male',28,'20121101','teacher',2100,401,1),
('jingliyang','female',18,'20110211','teacher',9000,401,1),
('jinxin','male',18,'19000301','teacher',30000,401,1),
('成龍','male',48,'20101111','teacher',10000,401,1),
('歪歪','female',48,'20150311','sale',3000.13,402,2),
('丫丫','female',38,'20101101','sale',2000.35,402,2),
('丁丁','female',18,'20110312','sale',1000.37,402,2),
('星星','female',18,'20160513','sale',3000.29,402,2),
('格格','female',28,'20170127','sale',4000.33,402,2),
('張野','male',28,'20160311','operation',10000.13,403,3),
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬銀','female',18,'20130311','operation',19000,403,3),
('程咬銅','male',18,'20150411','operation',18000,403,3),
('程咬鐵','female',18,'20140512','operation',17000,403,3)
;
查詢操作:
# 避免重複 distinct
select distinct post from employee;
# 通過四則運算查詢
select name,salary*12 from employee;
select name,salary*12 as Annual_salary from employee;
select name,salary*12 Annual_salary from employee; # as Annual_salary是給 salary*12 起了一個別名;as 可省略
# 定義顯示格式 (只是改變了顯示格式,不會改變資料在資料庫的儲存格式)
concat() 函式用於連結字串
select concat("員工號:",id,",","姓名:",name) as info,concat("年薪:",salary*12) as annual_salary from employee;
concat_ws() # 第一個引數可以作為分隔符
select concat_ws(":",name,salary*12) as annual_salary from employee;
where約束:
where語句中可以使用:
1. 比較運算子:>、<、>=、<=、 !=、( <>也表示不等於)
2. between 10 and 20 # 值在10到20之間
3. in(80,90,100) # 值是80或90或100
4. like "neo%"
pattern可以是%或_,
%表示任意個任意字元
_表示一個任意字元
5. 邏輯運算子:在多個條件直接可以使用邏輯運算子 and, or, not
主要用法:
where約束:
# 單條件查詢: select name from employee where post="sale"; # 多條件查詢: select name,salary from employee where post="teacher" and salary>10000; # 關鍵字between and select name,salary from employee where salary between 10000 and 20000; select name,salary from employee where salary not between 10000 and 20000; # 關鍵字 is Null:(判斷某個欄位是否為NULL不能用等號,要用is) select name,post_comment from employee where post_comment is Null; select name,post_comment from employee where post_comment is not Null; # MySQL中,空字串不等於 NULL,NULL是單獨的資料型別;判斷Null的時候必須用 is,如: where id is Null; # 關鍵字in集合查詢: select name,salary from employee where salary in (3000,4000,9000); select name,salary from employee where salary not in (3000,4000,9000); # 關鍵字like模糊查詢: 萬用字元:% select * from employee where name like "eg%"; 萬用字元:_ select * from employee where name like "ale_";
分組查詢:group by
# 分組發生在where之後,即分組是基於where之後得到的記錄而進行的 # 分組指的是將所有記錄按照某個相同欄位進行歸類,比如針對員工資訊表的職位分組,或者按照性別進行分組等
ONLY_FULL_GROUP_BY
# 檢視MySQL 5.7預設的sql_mode如下: mysql> select @@global.sql_mode; #ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION # 如果不設定ONLY_FULL_GROUP_BY,select的查詢結果預設值是組內的第一條記錄,這樣顯然是沒有意義的; # 設定 ONLY_FULL_GROUP_BY模式: set global sql_mode="ONLY_FULL_GROUP_BY"; # 注意: ONLY_FULL_GROUP_BY 的語義就是確定 select target list中的多有的值都是明確語義,簡單來說,在ONLY_FULL_GROUP_BY模式下,target list中的值要麼來自聚合函式的結果,要麼來自 group by list中的表示式的值(group_concat) # 去掉ONLY_FULL_GROUP_BY模式的設定方法: mysql> set global sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
聚合函式
# 聚合函式聚合的是組的內容;如果沒有進行 group by分組,則預設所以記錄是一組,所以此時也能用聚合函式 max() min() avg() sum() count()
示例:
select post,count(id) from employee group by post; # 只能檢視分組依據的欄位和使用聚合函式 # 注意:我們按照post欄位分組,那麼select查詢的欄位只能是post,想要獲取組內的其他相關資訊,需要藉助函式 # group by關鍵字和 group_concat() 函式一起使用 select post,group_concat(name) as emp_members from employee group by post; # 按照崗位分組,並檢視組內成員名 # group by和聚合函式一起使用 select post,avg(salary) as average_salary from employee group by post; # 按照崗位分組,並檢視每個組的平均工資 # 沒有分組的聚合函式: select count(*) from employee; select avg(salary) from employee;
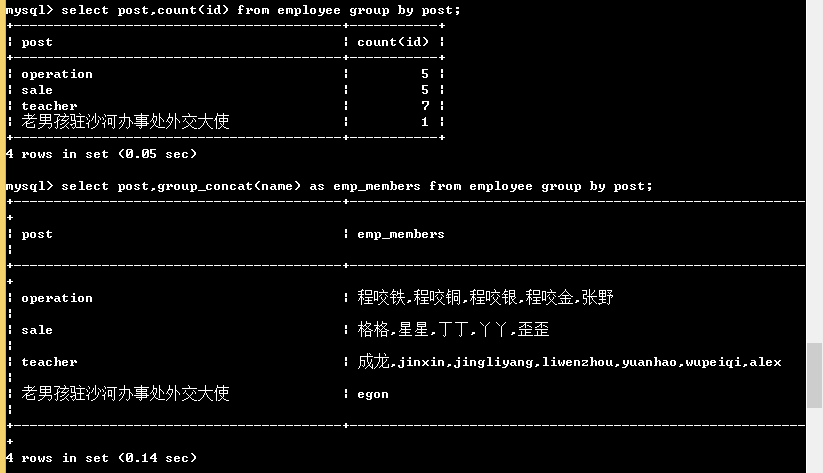
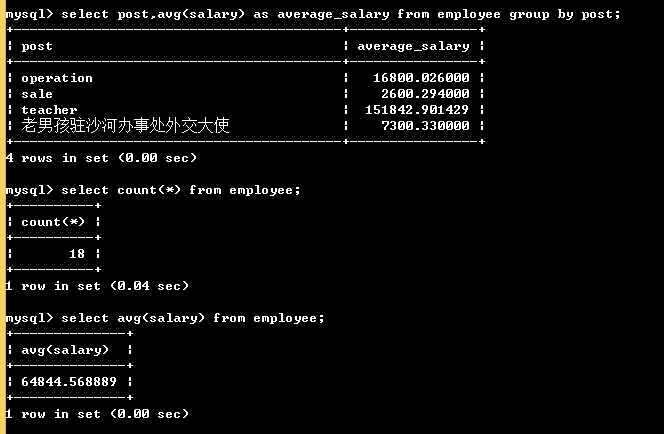
另外:如果我們用unique的欄位作為分組的依據,則每條記錄自成一組,這種分組也就沒了意義;多條記錄之間的某個欄位值相同,該欄位通常用來作為分組的依據
having過濾:
# having和where不一樣的地方: # 1. 執行優先順序:where>group by >having # 2. where 發生在分組 group by 之前,因而where中可以有任意欄位,但是絕對不能使用聚合函式 # 3. having發生在分組group by之後,因而having中可以使用分組的欄位,但卻無法直接取到其他欄位,其他欄位需要使用聚合函式
having中也可以用where中的邏輯,例如 and,or 等;having 跟where 用法一樣,只不過having是分組之後的過濾
錯誤用法示例:
mysql> select * from employee having salary > 100000; ERROR 1463 (42000): Non-grouping field 'salary' is used in HAVING clause # 報錯; having前面必須要有 group by mysql> select post,group_concat(name) from employee group by post having salary > 10000; #錯誤,分組後無法直接取到salary欄位 ERROR 1054 (42S22): Unknown column 'salary' in 'having clause'
正確用法如下:
# 1. 查詢各崗位平均薪資大於10000的崗位名、平均工資 select post,avg(salary) as average_salary from employee group by post having avg(salary) > 10000; # 2. 查詢各崗位平均薪資大於10000且小於20000的崗位名、平均工資 select post,avg(salary) as average_salary from employee group by post having avg(salary) between 10000 and 20000; # having的用法就是英語裡面的定語從句
order by排序:
select * from employee order by 欄位 asc; #升序排;預設 select * from employee order by 欄位 desc; #降序排 order by 欄位1 asc,欄位2 desc; # 先按照欄位1升序排,如果欄位1的值相同則按照欄位2降序排 e.g. select * from employee order by age asc,id desc;
執行順序證明:
select distinct post,count(id) as emp_number from db1.employee
where salary>1000
group by post
having count(id)>2 # having中的count(id)不能用 emp_number 來代替,因為是先執行 having後執行 distinct,所以此時還沒有 emp_number這個東西
order by emp_number desc # order by 中的count(id) 可以用 emp_number來代替,因為是先執行distinct後執行的order,執行完distinct之後就已經有了 emp_number
;
# 所以,優先順序順序是: from > where > group by > having > distinct > order by
limit限制條數:不管是書寫順序還是執行順序,limit都是在最後
select * from employee limit 3; # 3是限制條數;預設初始位置為0 select * from employee limit 0,3; # 從0開始列印3個 (不包含0) # 工資最高的那三個人的資訊: select * from employee order by salary desc limit 3; # 分頁列印: select * from employee limit 0,5; select * from employee limit 5,5; select * from employee limit 10,5; select * from employee limit 15,5;
正則查詢regexp: (regexp應該是regular expressioin的縮寫吧)
# select * from employee where name regexp "^jin.*(g|n)$"; # jin開頭,並且 g或者n結尾
多表查詢:(本質就是連表,通過連表將多張有關係的表連線在一起,得到一張虛擬表)
先建兩個表,用於下面所有的操作測試
# 建表
create table department(
id int,
name varchar(20)
);
create table employee(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
#插入資料
insert into department values
(200,'技術'),
(201,'人力資源'),
(202,'銷售'),
(203,'運營');
insert into employee(name,sex,age,dep_id) values
('egon','male',18,200),
('alex','female',48,201),
('wupeiqi','male',38,201),
('yuanhao','female',28,202),
('liwenzhou','male',18,200),
('jingliyang','female',18,204)
;
連線方式:
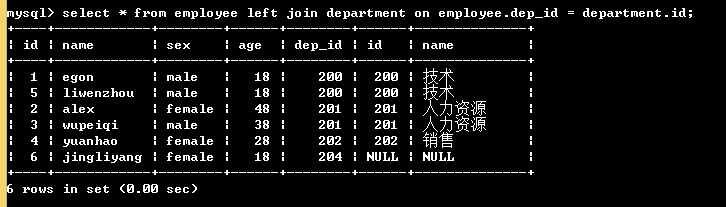
# 1. 內連線: 只取兩張表的共同部分 select * from employee inner join department on employee.dep_id = department.id; # 表employee內連線到表department,按照表employee中dep_id欄位等於表department中id欄位的方式連線 # 2. 左連結:在內連結的基礎上保留左表的記錄 select * from employee left join department on employee.dep_id = department.id; # 3. 右連結:在內連結的基礎上保留右表的記錄 select * from employee right join department on employee.dep_id = department.id; # 4. 全外連結: 在內連線的基礎上左右兩表的記錄都儲存 select * from employee left join department on employee.dep_id = department.id union select * from employee right join department on employee.dep_id = department.id;
內連線:

左連線:
右連線:

全外連線:
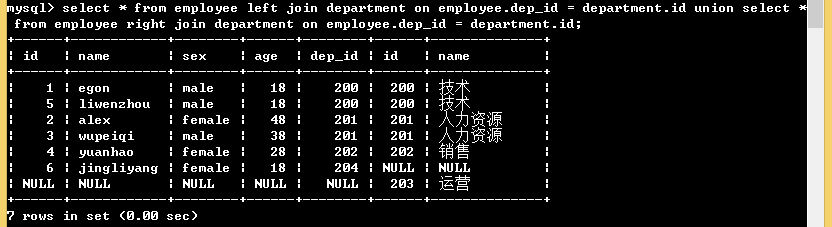
多表查詢示例:
笛卡爾積:
select * from employee,department;
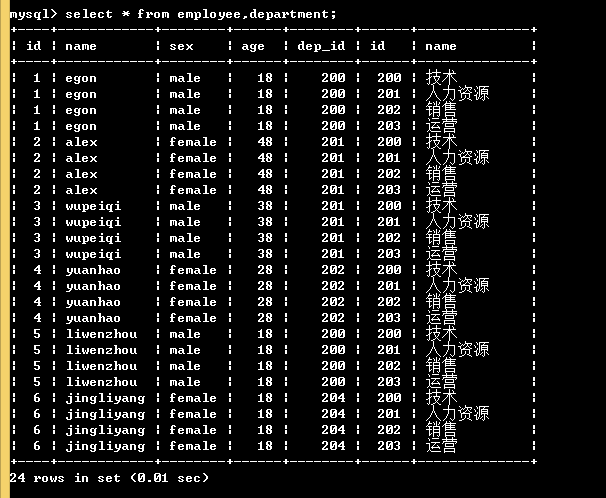
多表查詢原理:
select * from employee inner join department on employee.dep_id = department.id; # 通過這種方式能得到一個整合了表employee和表department的虛擬表

# 再對上面得到的虛擬表進行操作 select department.name,avg(age) from employee inner join department on employee.dep_id = department.id group by department.name having avg(age) > 30; # 多表查詢:把有關係的表通過連線的方式拼成一個整體(虛擬表),進而進行相應的關聯查詢(因為此時已經是一長表了)
SQL邏輯查詢語句執行順序:
一、SELECT語句關鍵字的定義順序:
select distinct <select_list>
from <left_table>
<join type> join <right_table>
on <join_condition>
where <where_condition>
group by <group_by_list>
having <having_condition>
order by <order_by_condition>
limit <limit_number>;
二、SELECT語句關鍵字的執行順序:
第一步: from <left_table> 第二步: on <join_condition> 第三步: <join_type> join <right_table> 第四步: where <where_condition> 第五步: group by <group_by_list> 第六步: having <having_condition> 第七步: select 第八步: distinct <select_list> 第九步: order by <order_by_condition> 第十步: limit <limit_number>
子查詢:
1. 帶 in 關鍵字的查詢:
# 查詢平均年齡在25歲以上的部門名 select name from department where id in (select dep_id from employee group by dep_id having avg(age) > 25); # (select dep_id from employee group by dep_id having avg(age) > 25)會有一個返回值,符合過濾條件的 dep_id;where id in (select dep_id from employee group by dep_id having avg(age) > 25) 就類似於 where id in (1,2,3) # 檢視技術部員工姓名 select name from employee where dep_id = (select id from department where name="技術"); # 檢視不足一人的部門名 # 分析:不足1人就是沒有人 select name from department where id not in (select distinct dep_id from employee) ; # (select distinct dep_id from employee) 通過去重得到有人的部門id, where id not in ...取反,即 department的id沒有在有人的部門id裡面
2. 帶比較運算子的子查詢
# 查詢大於所有人平均年齡的員工名和年齡 select name,age from employee where age > (select avg(age) from employee); # where後面不能直接寫成 where age > avg(age),因為where裡面不能使用聚合函式;所以先通過 (select avg(age) from employee)拿到 avg(age)
3. 帶exists關鍵字的子查詢 (exists是用於判斷是否存在的,返回的類似於bool值)
select * from employee where exists (select id from department where name="技術"); # 如果(select id from department where name="技術")成立(存在,此時where exists語句返回True),就執行 select * from employee; 如果不存在,就不執行select * 語句 # exists也可以not 取反
select 查詢語句可以用括號括起來,再用 as 起一個別名,就能當作一張表(臨時表)來使用,如下:
select * from (select name,age,sex from employee) as t1;
以另外一張employee表為例說明:
# 查詢每個部門最新入職的那名員工 報錯: select * from employee as t1 inner join (select post,max(hire_date) from employee group by post) as t2 on t1.post=t2.post where t1.hire_date=t2.max(hire_date); # 報錯原因:where中不能有聚合函式 正確: select * from employee as t1 inner join (select post,max(hire_date) as new_hire from employee group by post) as t2 on t1.post = t2.post where t1.hire_date = t2.new_hire; # 取別名後就是單純的呼叫了
許可權管理:略
Navicat工具:
批量加註釋:ctrl+?鍵
批量去註釋:ctrl+shift+?鍵
pymysql模組
pymysql基本使用:
通過pymysql模組能夠在python程式中操作MySQL資料庫;pymysql模組本質就是一個套接字客戶端軟體
import pymysql
username = input("username>>>:").strip()
password = input("password>>>:").strip()
# 建連結
conn = pymysql.connect(host="192.168.18.2",port=3306,user="root",password="123",db="db4",charset="utf8") # 得到一個連結物件; # charset中的utf8不能加 - ,因為mysql中沒加
# 拿到一個遊標(cursor)
cursor = conn.cursor() # 得到一個遊標物件
# 給遊標提交命令,執行sql語句
sql = "select * from userinfo where username='%s' and password='%s' " %(username,password) # sql語句中的username和password要和db4.userinfo這張表中的欄位一樣
print(sql)
rows = cursor.execute(sql) # 把sql語句提交給cursor去執行; # execute() 不是執行的結果,而是受影響的行數(rows)
cursor.close()
conn.close() # 把資源回收
# 進行判斷
if rows:
print("登入成功")
else:
print("登入失敗")
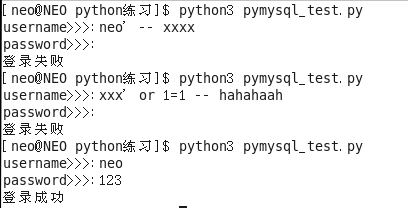
但上面的程式有一個漏洞:
# 在MySQL中, --空格 後面的內容都會被註釋掉(兩個橫槓後面跟一個空格),所以在你的python程式中輸入: username>>>:neo' -- xxxx 不輸密碼,也能夠成功登入
並且
# 輸入: username>>>:xxx' or 1=1 -- hahahaah 不輸密碼,也可以登入

解決辦法:利用pymysql模組的sql注入
pymysql模組之sql注入:
import pymysql
username = input("username>>>:").strip()
password = input("password>>>:").strip()
# 建連結
conn = pymysql.connect(host="192.168.18.2",port=3306,user="root",password="123",db="db4",charset="utf8")
# 拿到一個遊標(cursor)
cursor = conn.cursor() # 得到一個遊標物件
# 給遊標提交命令,執行sql語句
sql = “select * from userinfo where username=%s and password=%s” # 不要自己拼接字串,利用 pymysql的execute拼接字串; # 佔位符也不要再加引號
rows = cursor.execute(sql,(username,password)) # 第一個引數還是傳入要執行的sql語句;第二個引數傳入一個元組,元組裡面放入sql語句裡面的佔位符,通過這種方式拼接字串,能把其中的特殊字元處理掉
cursor.close()
conn.close()
# 進行判斷
if rows:
print("登入成功")
else:
print("登入失敗")
pymysql模組之增刪改:
import pymysql
# 建連結
conn = pymysql.connect(host="192.168.18.2",port=3306,user="root",password="123",db="db4",charset="utf8")
# 拿到遊標
cursor = conn.cursor()
# 執行sql語句
# 增刪改
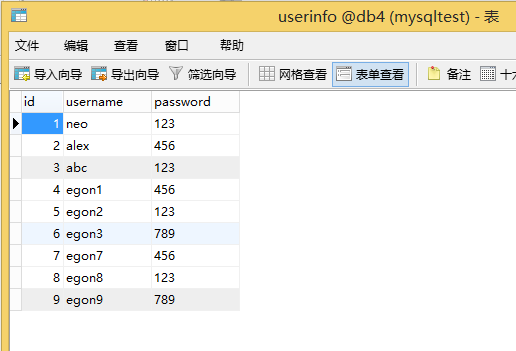
sql = "insert userinfo(username,password) values(%s,%s)"
print(sql)
rows = cursor.execute(sql,("abc","123"))
conn.commit() # 修改的資料要生效,必須在cursor,conn關閉之前 conn.commit()
# 關閉
cursor.close()
conn.close()
插入多條記錄:
# 插入多條記錄
rows = cursor.executemany(sql,[("egon1","456"),("egon2","123"),("egon3","789")]) # 利用executemany(),列表中放入多個元組
lastrowid用法:查詢你即將插入的資料是從第幾行開始的
import pymysql
# 建連結
conn = pymysql.connect(host="192.168.18.2",port=3306,user="root",password="123",db="db4",charset="utf8")
# 拿到遊標
cursor = conn.cursor()
# 執行sql語句
sql = "insert userinfo(username,password) values(%s,%s)"
# 插入多條記錄
rows = cursor.executemany(sql,[("egon7","456"),("egon8","123"),("egon9","789")]) # 利用executemany(),列表中放入多個元組
print(cursor.lastrowid) # cursor.lastrowid 是你上面程式碼插入的時候,是從第幾行開始插入的
conn.commit() # 修改的資料要生效,必須在cursor,conn關閉之前 conn.commit()
# 關閉
cursor.close()
conn.close()
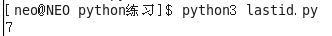
刪改就是把上述例子中的sql語句改成刪改的sql語句就行了
pymysql模組之查詢
import pymysql
conn = pymysql.connect(host="192.168.18.2",port=3306,user="root",password="123",db="db4",charset="utf8")
cursor = conn.cursor(pymysql.cursors.DictCursor) # cursor()中如果什麼都不寫,查詢出來的資料是元組的形式;如果指明瞭 pymysql.cursors.DictCursor,查詢結果是字典的形式,字典的key是表的欄位
rows = cursor.execute("select * from userinfo")
print(cursor.fetchone())
print(cursor.fetchone())
print(cursor.fetchone())
print(cursor.fetchone())
print(cursor.fetchone())
print(cursor.fetchone())
print(cursor.fetchone())
print(cursor.fetchone())
# 執行過程分析: cursor.execute("select * from userinfo")給MySQL服務端傳送了查詢語句,服務端查完之後把查詢結果返回給服務端,服務端收到後把全部結果放到了管道里面,fetchone()一次就取出一條結果;取完之後再去就是None
# fetch還有兩種用法:
# 1. cursor.fetchmany(3) # 一次取3條;取出來的結果放到一個列表中,由於已經指定了 pymysql.cursors.DictCursor,所以列表中是一個個字典
# 2. cursor.fetchall() # 一次全部取完,結果放到一個列表中;取完之後再fetchall會得到一個空列表
cursor.close()
conn.close()
fetchone:

fetchmany:

fetchall:

cursor.scroll用法:移動管道中的游標
import pymysql
conn = pymysql.connect(host="192.168.18.2",port=3306,user="root",password="123",db="db4",charset="utf8")
cursor = conn.cursor(pymysql.cursors.DictCursor)
rows = cursor.execute("select * from userinfo")
# cursor.scroll(3,mode="absolute") # 相對絕對位置移動:從管道最開始的位置跳過去3條
# cursor.scroll(3,mode="relative") # 相對當前位置移動:從游標所在管道的當前位置跳過去3條
cursor.scroll(3,mode="absolute")
print(cursor.fetchone()) # 跳過前三條,直接從第四條開始取
cursor.close()
conn.close()
相對絕對位置移動

相對當前位置移動
print(cursor.fetchone()) cursor.scroll(3,mode="relative") print(cursor.fetchone()) # 從第二條開始跳過取3個開始取

MySQL內建功能:
檢視:
檢視一個虛擬表(非真實存在),其本質是【根據SQL語句獲取動態的資料集,併為其命名】,使用者使用時只需使用【名稱】即可獲取結果集,可以將結果當作表來使用;但是不推薦使用檢視,因為擴充套件SQL極不方便
建立檢視:
# 語法: create view 檢視名稱 as sql語句 create view teacher_view as select tid from teacher where tname='李平老師'; #於是查詢李平老師教授的課程名的sql可以改寫為 mysql> select cname from course where teacher_id = (select tid from teacher_view);
修改檢視(往檢視中插入資料),原始表也跟著改
修改檢視:
語法:ALTER VIEW 檢視名稱 AS SQL語句 mysql> alter view teacher_view as select * from course where cid>3;
刪除檢視:
# 語法:DROP VIEW 檢視名稱 DROP VIEW teacher_view
函式:
date_format(date相關欄位,date格式) # 第一個引數寫date的相關欄位,第二個引數寫所需要的date格式,如:"%Y-%m-%d";
datediff(current_date,sale_date) # current_date和sale_date之間的天數間隔
示例:
select item_id,count(distinct date_format(sale_date,"%Y-%m-%d")) as day_num from txn where datediff(current_date,sale_date) <=10 group by item_id having day_num >=5 order by day_num desc; # current_date也是一個函式,表示當天的日期
控制流函式:
1、case when condition1 then result1 ... else default end
# 如果 conditionN是真,則返回 resultN,否則返回default
2、case test when value1 then result1... else default end
# 如果test 和valueN相等,則返回 resultN,否則返回default
如下:
查詢班級資訊,包括班級id、班級名稱、年級、年級級別(1為低年級,2為中年級,3為高年級)
select cid as 班級id,caption as 班級名稱,gname as 年級, (case grade_id when 1 then "低" when 2 then "中" else "高" end) as "年級級別" from class inner join class_grade on class.grade_id=class_grade.gid;