
單鏈表的插入,刪除,查詢,轉置
單鏈表的定義
線性表的鏈式儲存又稱為單鏈表,它是指通過任意一組的儲存單元來儲存線性表中的資料元素。 在單鏈表中,每個節點包含一個指向連結串列下一節點的指標。連結串列最後一個節點的指標欄位的值為NULL,提示連結串列後面不再有其它節點。它是非隨機存取的儲存結構,操作時只能從表頭開始遍歷。
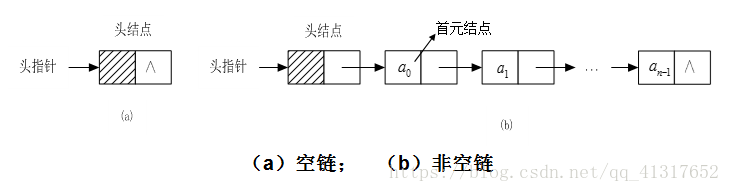
通常用 “頭指標” 標識一個單鏈表,頭指標為“NULL“ 表示空表,為了操作上的方便,在單鏈表的第一個節點前附加一個節點,稱頭節點 ,引入頭節點的兩個優點:
1)由於開始節點的位置被存放被存放在頭節點的指標域,所以再連結串列第一個位置的操作和在表的其他位置上操作一致,無需特殊對待
2)無論連結串列是否空,其頭指標是指向頭節點的非空指標(空表中頭節點的指標域為空),因此空表的和非空表的處理也就統一了
因此以下討論基於帶有頭節點的單鏈表
採用資料結構:
typedef struct node{
ElemType data;
struct node * next;
}node;1.建立
1)頭插法
node *creat(){
node *head=new node,*p,*pre;
head->next =NULL; //original
pre=head;
int x;
scanf("%d",&x);
while(x!=-1){
p=new node;
p->data =x;
p->next 頭插法雖簡單,但生成連結串列中節點的次序與輸入順序不一致,若希望兩者次序一致,可採用頭插法。
2)尾插法
node *creat(){
node *head=new node;
head->next =NULL;
int x;
cin>>x;
node *pre=head,*p;
while 2.查詢
1)按序號查詢
2)按值查詢
這兩種都比較簡單,直接遍歷連結串列搜尋,符合條件時輸出,此不贅述
3.刪除節點
1)按序號刪除
關鍵點:遍歷查詢單鏈表中待刪除節點的前驅
node* Del_node_id( node *head,int i){
node *p=head,*q;
int count=0;
while(p->next !=NULL){
count++;
q=p->next; // 找q前驅
if(count==i){
p->next =q->next;
delete q;
return head;
}
p=p->next;
}
//i 不符合實際要求
printf("你的刪除元素位置有錯!\n");
return head;
} 2)按元素值刪除
node *Del_node_value(node *head,int value){
node *p=head,*q;
while(p->next !=NULL){
q=p->next ; //找q前驅節點
if(p->next->data==value ){
p->next =q->next ;
delete q;
return head;
}
p=p->next ; //指標後移
}
printf("此連結串列沒有值為value的節點!\n");
return head;
}刪除過程注意不要斷鏈即可
那麼問題來了:如何刪除單鏈表中的重複節點(保留第一個重複節點)
思路1:兩層迴圈,暴力列舉刪除,時間複雜度O(n^2),空房間複雜度O(1)
void Del_linklist(node * H){
node *p,*q,*r;
p=H->next;
if(p!=NULL) //非空連結串列
while(p->next){ //外層,需大於1個節點
q=p-next;
while(q){ //內層,p的下一個節點開始遍歷
if(q->next->data==p->data){ //刪除符合條件的節點
r=q->next;
q->next=r->next;
delete r;
}
q=q->next;
}
p=p->next;
}
} 思路2:改進第一種做法,採用空間換時間,使用輔助陣列記錄連結串列已出現的節點,從而只對連結串列進行一邊掃描,邊遍歷邊標記,符合刪除條件,則delete。時間複雜度O(n),空房間複雜度O(n)
node *delList(node *head){
node *r,*p=head->next;
r=p;
if(p==NULL) return NULL;
fill(vis,vis+1000,false);
while(p!=NULL){
if(vis[p->data]==true){
r->next =p->next ;
delete p;
p=r->next ;
}
else{
vis[p->data]=1;
r=p;
p=p->next ;
}
}
return head;
}類似問題:如何刪除連結串列中重複元素(重複元素全部刪除)
提示:空間換時間,採用Hash[ ]雜湊,一遍掃描標記,一遍掃描刪除,只需兩次遍歷。時間複雜度O(n),空房間複雜度O(n)。
node *del(node *head){
fill(hash,hash+maxn,0);
node *r,*p=head->next;
r=head;
if(p==NULL) return NULL;
while(p){ //一遍掃描標記
hash[p->data]++;
//cout<<p->data <<hash[p->data]<<endl;
p=p->next ;
}
//開始開始嘍
p=r-next;
while(p!=NULL){ //一遍掃描刪除
if(hash[p->data]>1){
r->next =p->next ;
delete p;
p=r->next ;
}else{
r=p;
p=p->next ;
}
}
return head;
}4.插入節點
關鍵點:找到待插入節點位置的前驅
node* Insert_linklist(node *head,int i,int value){
node *p=head,*q;
int count=0;
while(p->next !=NULL){
count++;
if(count==i) //找待插入節點的前驅指標 p
break;
p=p->next;
} //開始插入
q=new node;
q->data =value;
q->next =p->next ;
p->next =q;
return head;
} 5.逆置連結串列
關鍵點:不斷遍歷連結串列,將後一個節點的next指向前一個節點
最後頭節點掛到原連結串列的尾部
node* Transpose_linklist(node *H){
node*p,*q,*pr;
p=H->next ;
H->next =NULL; //摘除頭節點
q=NULL;
while(p){
pr=p->next;
p->next=q; //後一個節點的next指向前一個節點
q=p; //尾指標為空
p=pr; //指標後移
}
H->next =q; //頭節點掛到原連結串列的尾部
printf("轉置後連結串列:\n");
} 6.列印連結串列
void output_linklist(node* H){
node *p=H->next ;
while(p){
printf("%2d",p->data );
p=p->next ;
}
}7.程式碼
#include<cstdio>
#define ElemType int
struct node{
ElemType data;
node * next;
};
//尾插法建立單鏈表
node *creat1( ){
node*head,*pre,*p;
int x;
scanf("%d",&x);
head=new node;
head->next=NULL;
pre=head;
while(x!=-1){
p=new node;
p->data=x;
p->next=NULL;
pre->next=p;
pre=p;
scanf("%d",&x);
}
return head;
}
//頭插法建立單鏈表
/*
node *creat2(){
* node *head=new node,*p,*pre;
* head->next =NULL; //original
* pre=head;
* int x;
* scanf("%d",&x);
* while(x!=-1){
* p=new node;
* p->data =x;
* p->next =pre->next ; //每個節點插入O(1),總O(n)
* pre->next =p;
* scanf("%d",&x);
* }
* return head;
}*
*/
//轉置單鏈表
node* zhuanzhi_linklist(node *H)
{
node*p,*q,*pr;
p=H->next ;
H->next =NULL; //摘除頭節點
q=NULL;
while(p)
{
pr=p->next;
p->next=q;
q=p; //尾指標為空
p=pr; //指標後移
}
H->next =q;
printf("轉置後連結串列:\n");
}
//刪除單鏈表中重複的節點,時間複雜度o(n^2)
//hash[]後刪除效率高
void Del_linklist(node * H){
node *p,*q,*r;
p=H->next;
if(p!=NULL)
while(p->next) {
q=p;
while(q->next)
{
if(q->next->data==p->data)
{
r=q->next;
q->next=r->next;
delete r;
}
q=q->next;
}
p=p->next;
}
}
//刪除某位置節點
node* Del_node_id( node *head,int i){
node *p=head,*q;
int count=0;
while(p->next !=NULL){
count++;
q=p->next; // 找q前驅
if(count==i){
p->next =q->next;
delete q;
return head;
}
p=p->next;
}
//i不符合實際要求
printf("你的刪除元素位置有錯!\n");
return head;
}
//刪除值為value的節點
node *Del_node_value(node *head,int value){
node *p=head,*q;
while(p->next !=NULL){
q=p->next ;
if(p->next->data==value ){
p->next =q->next ;
delete q;
return head;
}
p=p->next ;
}
printf("此連結串列沒有值為value的節點!\n");
return head;
}
//新增 n 個節點
node *Add_linklist(node *head){
node *p=head,*q;
while(p->next!=NULL){ //此處的 p 應指向尾節點,方便新增新的節點
p=p->next ;
}
int x;
scanf("%d",&x);
while(x!=-1){
q=new node;
q->data =x;
q->next =NULL;
p->next =q;
p=q;
scanf("%d", &x );
}
return head;
}
//插入節點
node* Insert_linklist(node *head,int i,int value){
node *p=head,*q;
int count=0;
while(p->next !=NULL){
count++;
if(count==i) //找帶插入節點位置的前驅指標 p
break;
p=p->next;
}
q=new node;
q->data =value;
q->next =p->next ;
p->next =q;
return head;
}
//列印節點
void output_linklist(node* H)
{
node *p=H->next ;
while(p)
{
printf("%2d",p->data );
p=p->next ;
}
}
int main(){
node*head=creat1();
printf("列印連結串列:\n");
output_linklist(head);
printf("\n");
Transpose_linklist(head);
output_linklist(head);
printf("\n");
Del_linklist(head);
printf("刪除重複節點,保留第一個:\n");
output_linklist(head);
printf("\n");
printf("輸入尾部要新增節點,-1表示結束:\n");
head=Add_linklist(head);
output_linklist(head);
printf("\n");
int i,value;
printf("輸入要插入的元素位置及元素值:\n");
scanf("%d%d",&i,&value);
Insert_linklist(head, i, value);
output_linklist(head);
printf("\n");
printf("please input del posttion:\n");
int j;
scanf("%d",&j);
Del_node_id(head, j);
output_linklist(head);
printf("\nplease input del value:\n");
scanf("%d",&value);
Del_node_value(head, value);
output_linklist(head);
return 0;
}